Performance and Efficiency: Working with HTTP/3
HTTP/3 is on the horizon, but many aren’t even familiar with HTTP/2 yet. Find out what HTTP/3 means for web development, administration, and the internet.

HTTP/3 is on the horizon, but many aren’t even familiar with HTTP/2 yet. Find out what HTTP/3 means for web development, administration, and the internet.

Brian was a system administrator and network engineer before turning to software development in an effort to automate himself out of a job.
HTTP/3 is on the horizon, following hot on the heels of HTTP/2—which is arguably still very young itself. Given it took 16 years to go from HTTP/1.1 to HTTP/2, should anyone really be concerned with HTTP/3?
The short answer: Yes, it’s important, and you should be up to speed with it. It’s just like how HTTP/2 made significant changes from HTTP/1.1 by switching from ASCII to binary. HTTP/3 again makes significant changes, this time by switching the underlying transport from TCP to UDP.
Although HTTP/3 is still in the design stage with the official specification being a draft, it’s already being deployed and there’s a good chance that you’ll find a version of it running on your network today.
But there are some new dilemmas posed by how HTTP/3 works. Also, what’s the benefit? And what do network engineers, system administrators, and developers need to know?
TL;DR
- Faster websites are more successful.
- HTTP/2 brings a big performance boost because it solves the HTTP head-of-line blocking problem (HOL). It introduces request/response multiplexing, binary framing, header compression, stream prioritization, and server push.
- HTTP/3 is even faster because it incorporates all of HTTP/2 and solves the TCP HOL blocking problem as well. HTTP/3 is still just a draft but is already being deployed. It is more efficient, uses fewer resources (system and network), requires encryption (SSL certificates are mandatory), and uses UDP.
- Although web browsers are likely to continue to support the older versions of HTTP for some time, performance benefits and prioritization of HTTP/3-savvy sites by search engines should drive adoption of the newer protocols.
- SPDY is obsolete and anyone using it should replace it with HTTP/2.
- Today's sites should already be supporting both HTTP/1.1 and HTTP/2.
- In the near future, site owners will probably want to be supporting HTTP/3 as well. However, it's more controversial than HTTP/2, and we'll likely see a lot of larger networks simply blocking it instead of taking the time to deal with it.
The Main Issue: Performance and Efficiency
Site and app developers generally build with the intent that their creations are actually used. Sometimes the audience base is finite, but often the idea is just to get as many users as possible. Naturally, the more popular a website becomes, the more revenue it can make.
A 100-millisecond delay in website load time can hurt conversion rates by 7 percent.
Akamai Online Retail Performance Report: Milliseconds Are Critical (2017)
Put another way, an eCommerce site with sales of $40,000 per day would lose a million dollars annually due to such a delay.
It’s also no secret that the performance of a site is absolutely critical to a site becoming more popular. Online shopping research continues to find links between increased bounce rates and longer loading times, and between shopper loyalty and website performance during the shopping experience.
Research also found that:
- 47% of consumers expect a web page to load in 2 seconds or less.
- 40% of people abandon a website that takes more than 3 seconds to load.
And that was the state of online shopper patience as of over a decade ago. So performance is critical, and HTTP/2 and HTTP/3 both mean better website performance.
HTTP/2? …What’s That?
A good understanding of the HTTP/2 protocol is crucial to understanding HTTP/3. First of all, why was there any need for HTTP/2?
HTTP/2 started out as a Google project called SPDY, the result of a study that reported that the biggest performance problem on the web was latency. The author concluded that “more bandwidth doesn’t matter (much)”:
If we make an analogy between plumbing and the Internet, we can consider the bandwidth of the Internet to be like the diameter of the water pipe. A larger pipe carries a larger volume of water, and hence you can deliver more water between two points.
At the same time, no matter how big your pipe is, if the pipe is empty, and you want to get water from one point to the other, it takes time for water to travel through the pipe. In Internet parlance, the time it takes for water to travel from one end of the pipe to the other and back again is called the round trip time, or RTT.
Mike Belshe
In the study, reducing page load time was the goal. It showed that increasing bandwidth helps initially, as going from 1 Mbps to 2 Mbps halves the page load time. However, the benefits plateau very quickly.
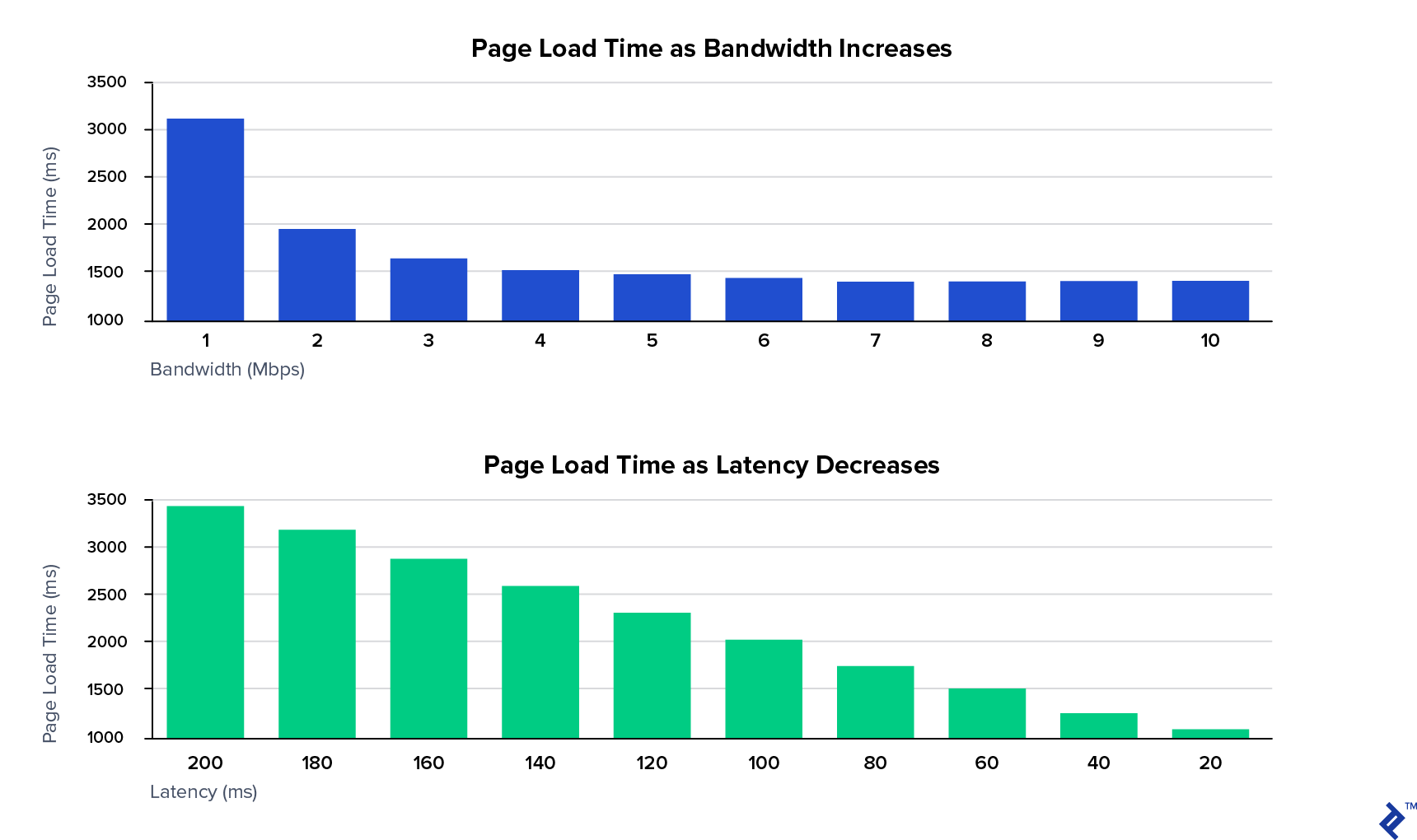
In contrast, decreasing latency has a constant benefit and achieves the best results.
HTTP HOL: The Head-of-line Blocking Problem
The main cause of latency within the HTTP/1 protocol is the head-of-line blocking problem. Web pages (almost always) require multiple resources: CSS, JavaScript, fonts, images, AJAX/XMR, etc. This means the web browser needs to make multiple requests to the server. However, not all of the resources are required for the page to become useful.
With HTTP/1.0 it was necessary for the browser to fully complete a request, including fully receiving the response, before starting the next request. Everything had to be done in sequence. Each request would block the line of requests, hence the name.
In an attempt to compensate for the HOL blocking problem, web browsers make multiple simultaneous connections to a single server. But they have had to arbitrarily limit this behavior: Servers, workstations, and networks can become overloaded with too many connections.
HTTP/1.1 introduced several improvements to help tackle the issue. The main one is pipelining, allowing web browsers to start new requests without needing to wait for previous requests to complete. This significantly improved loading times in low-latency environments.
But it still requires all of the responses to arrive sequentially in the order that they were made, so the head of the line is still blocked. Surprisingly, a lot of servers still don’t take advantage of this feature.
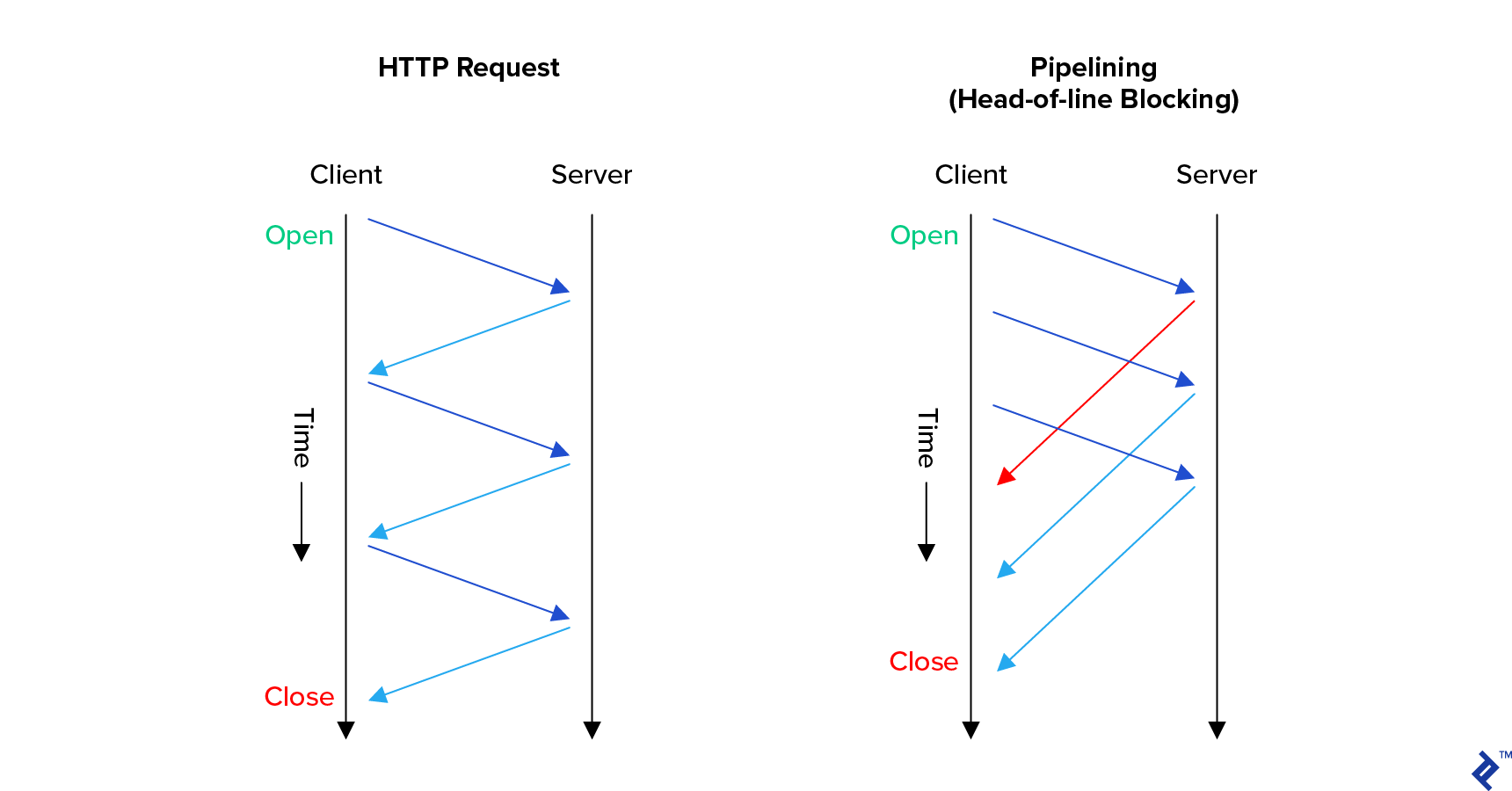
Interestingly, HTTP/1.1 also introduced keep-alive, which allowed browsers to avoid the overhead of creating a new TCP connection for each HTTP request. This was an early attempt to solve a TCP-derived performance issue. It was so ineffective that most performance experts actually discourage it because it bogs down the server with too many inactive connections. We’ll take a closer look at TCP below, as well as how this issue was fixed by HTTP/2.
HTTP/2’s HTTP HOL Blocking Solution
HTTP/2 introduced request-response multiplexing over a single connection. Not only can a browser start a new request at any time, but the responses can be received in any order—blocking is completely eliminated at the application level.
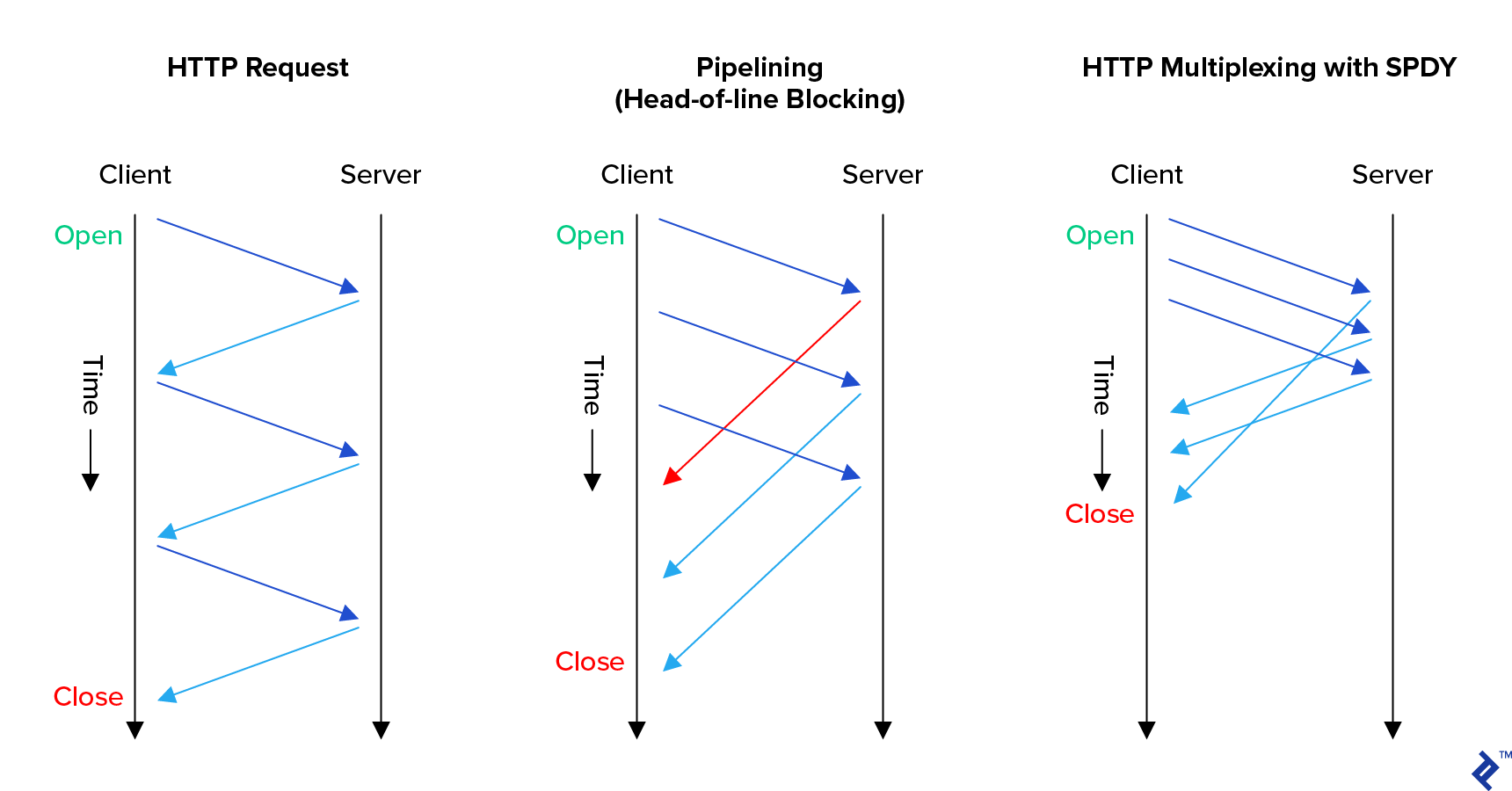
As a direct result, this means HTTP/2-savvy web servers can maximize efficiency—more on that later.
Although request-response multiplexing is the headline feature for HTTP/2, it includes several other significant features. Readers may note that they’re all somewhat related.
HTTP/2 Binary Framing
HTTP/2 switches the HTTP protocol standard from an inefficient human-readable ASCII request-response model to efficient binary framing. It’s no longer just a request and a response:
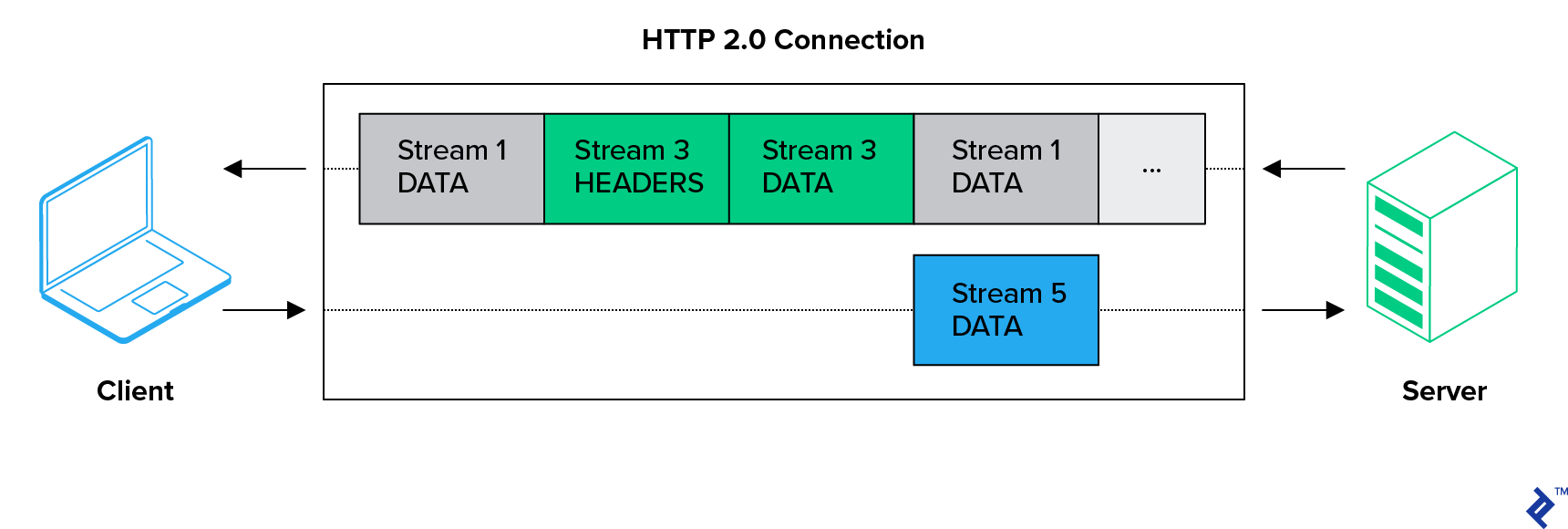
With HTTP/2, browsers talk with servers over bidirectional streams with multiple messages, each consisting of multiple frames.
HTTP/2 HPACK (Header Compression)
HTTP/2’s new header compression, using the HPACK format, saves a ton of bandwidth for most sites. This is because the majority of headers are the same for the requests sent within a connection.
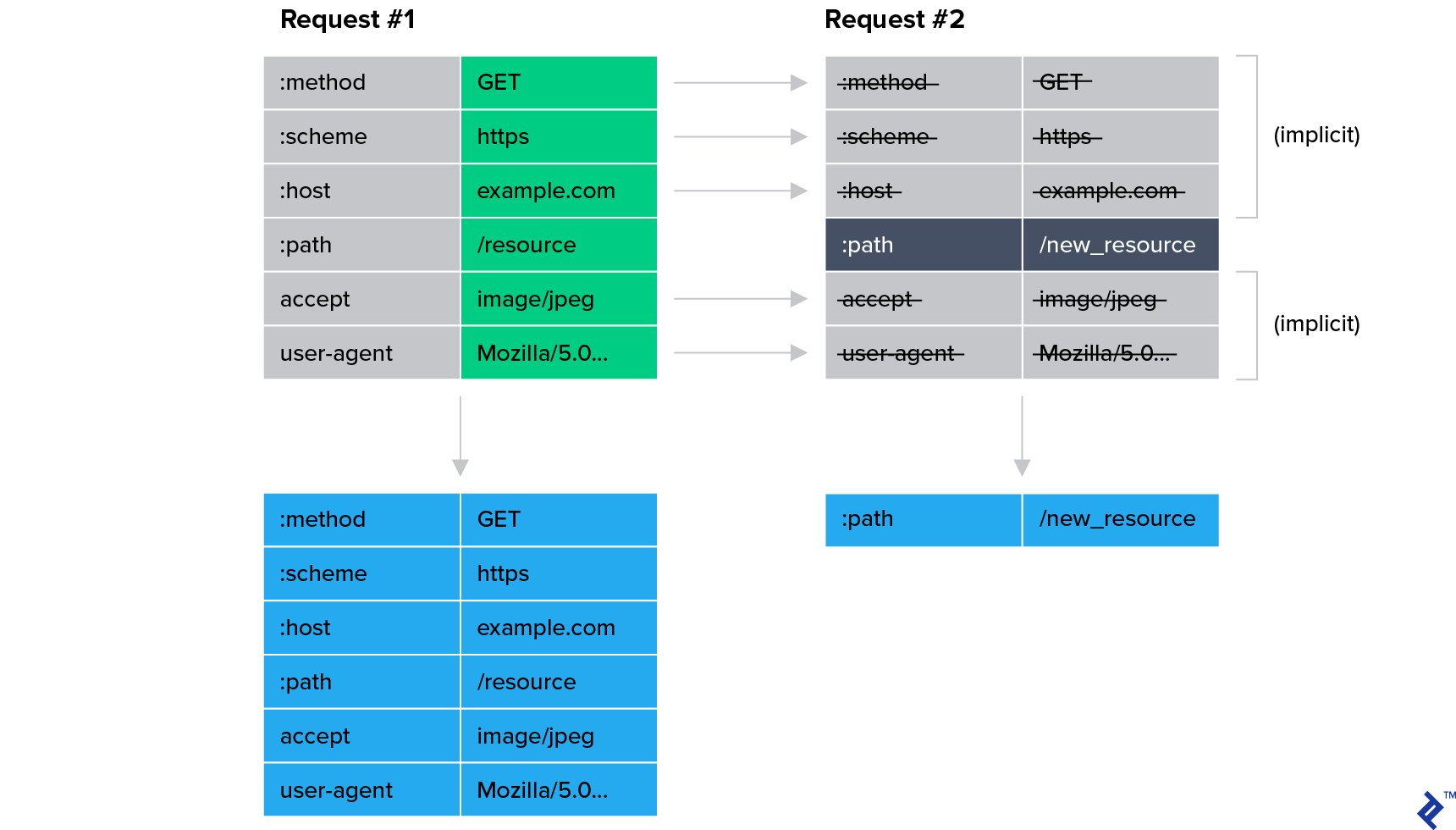
Cloudflare reports significant bandwidth savings thanks to HPACK alone:
- 76% compression for ingress headers
- 53% reduction in total ingress traffic
- 69% compression for egress headers
- 1.4% to 15% reduction in total egress traffic
Of course, using less bandwidth generally means a faster website.
HTTP/2 Stream Prioritization and Server Push
Here’s where HTTP/2’s multiplexing really allows the server to maximize efficiency. Multiplexing does help serve up faster resources (e.g., memory-cached JavaScript) before slower ones (e.g., large images, database-generated JSON, etc.). But it also allows for an additional performance boost via HTTP/2’s stream prioritization.
Stream prioritization helps ensure that almost-ready aspects of a page are completed in full without having to wait for other resource-intensive requests to finish. This is accomplished through a weighted dependency tree. This tree is used to inform the server which responses it should be allocating the most system resources to serving.
This is particularly important for progressive web applications (PWAs). For example, say a page has four JavaScript files. Two are for page functionality and two are for ads. The worst-case scenario is to load half of the functional JS and half of the advertising JS and then go on to load big images, before loading any of the remaining JS. In that case, nothing on the page works initially, because everything has to wait for the slowest resource.
With stream prioritization, web browsers can instruct the server to send both of the page functionality JS files before sending any of the advertising JavaScript files. This way users don’t have to wait for ads to fully load before using the functionality of the page. Although the overall loading time hasn’t improved, the perceived performance has been significantly increased. Unfortunately, this behavior within the web browser is still mostly a matter for algorithms, rather than being something specified by web developers.
Along the same lines, HTTP/2’s server push feature allows the server to send responses to the browser for requests that it hasn’t made yet! The server can take advantage of gaps in transmission, efficiently using bandwidth by preloading into the browser resources that the server knows that it will request soon. Part of the hope here is to eliminate the practice of resource inlining, which just bloats resources and makes them take longer to load.
Unfortunately, both of these features need a lot of careful configuration by web developers to really succeed. Simply enabling them isn’t enough.
HTTP/2 clearly brings many potential advantages—some of them cheaper to leverage than others. How are they faring in the real world?
HTTP vs HTTP/2 Adoption
SPDY was created in 2009. HTTP/2 was standardized in 2015. SPDY became the name of an unstable development branch of the code, with HTTP/2 becoming the final version. The result is that SPDY has become obsolete, and HTTP/2 is commonly the standard that everyone follows.
After standardization, adoption of HTTP/2 (or “h2”) grew quickly to around 40% of the top 1,000 websites. This was mostly driven by large hosting and cloud providers deploying support on behalf of their customers. Unfortunately, several years later, HTTP/2 adoption has slowed and the majority of the internet is still on HTTP/1.
Lack of Browser Support for HTTP/2 Clear Text Mode
There were many calls for HTTP/2 to make encryption a required part of the standard. Instead, the standard defined both encrypted (h2) and clear text (h2c) modes. As such, HTTP/2 could replace HTTP/1 entirely.
Despite the standard, all current web browsers are only supporting HTTP/2 over encrypted connections and are intentionally not implementing clear text mode. Instead, browsers rely on HTTP/1 backward compatibility mode to access insecure servers. This is a direct result of an ideological push towards making the web secure by default.
Why HTTP/3? And How Is It Different?
With the HTTP head-of-line blocking problem now fixed by HTTP/2, protocol developers have turned their attention to the next biggest latency driver: the TCP head-of-line blocking problem.
Transmission Control Protocol (TCP)
IP (internet protocol) networks are based around the idea of computers sending each other packets. A packet is just data with some addressing information attached to the top.
But applications usually need to deal with streams of data. To achieve this illusion, the transmission control protocol (TCP) presents applications a pipe through which a stream of data can flow. As with most pipes, there is a guarantee that data will exit the pipe in the same order that it enters, also known as “first in, first out” (FIFO). These characteristics have made TCP very useful and very widely adopted.
As part of the data delivery guarantees that TCP provides, it has to be able to handle a wide variety of situations. One of the most complex problems is how to deliver all data when a network is overloaded, without making the situation worse for everybody. The algorithm for this is called congestion control and is a constantly evolving part of internet specifications. Without sufficient congestion control, the internet grinds to a halt.
In October of '86, the Internet had the first of what became a series of 'congestion collapses.' During this period, the data throughput from LBL to UC Berkeley (sites separated by 400 yards and three IMP hops) dropped from 32 Kbps to 40 bps.
V. Jacobson (1988)
That’s where the TCP head-of-line blocking problem comes in.
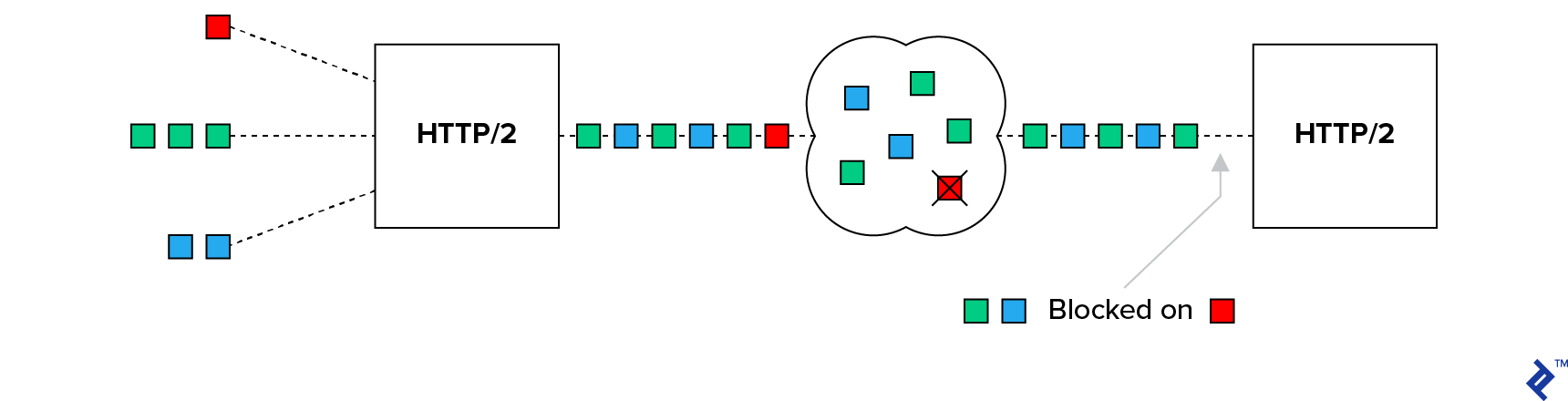
TCP HOL Blocking Problem
TCP congestion control works by implementing backoff and retransmission mechanisms for packets, used whenever packet loss is detected. Backoff is intended to help calm the network. Retransmission ensures that the data is eventually delivered.
This means that TCP data can arrive at the destination out of order, and it’s the responsibility of the receiving party to reorder the packets before reassembling them into the stream. Unfortunately, this means that a single lost packet can cause the whole TCP stream to be paused while the server waits for its retransmission. Hence, the head of the line is blocked.
Another project from Google aimed to solve this problem by introducing a protocol called QUIC.
The QUIC protocol is built on top of UDP instead of TCP, and QUIC is forming the basis for HTTP/3.
What Is UDP?
The user datagram protocol (UDP) is an alternative to TCP. It doesn’t provide the illusion of a stream or the same guarantees that TCP offers. Instead, it simply provides an easy way to place data into a packet, address it to another computer, and send it. It is unreliable, unordered, and does not come with any form of congestion control.
Its purpose is to be lightweight and provide the minimum features necessary to allow communication. This way the application can implement its own guarantees. This is often very useful in real-time applications. For example, in phone calls, users generally prefer to receive 90% of the data immediately, rather than 100% of the data eventually.
HTTP/3’s TCP HOL Solution
Solving the TCP HOL blocking problem required more than just switching to UDP, as it’s still necessary to guarantee delivery of all the data and avoid network congestion collapses. The QUIC protocol is designed to do all of this by providing an optimized HTTP over UDP–type experience.
As QUIC takes over control of stream management, binary framing, etc., not a lot is left for HTTP/2 to be doing when running on top of QUIC. This is part of the driving factor towards this new combination of QUIC + HTTP being standardized as HTTP/3.
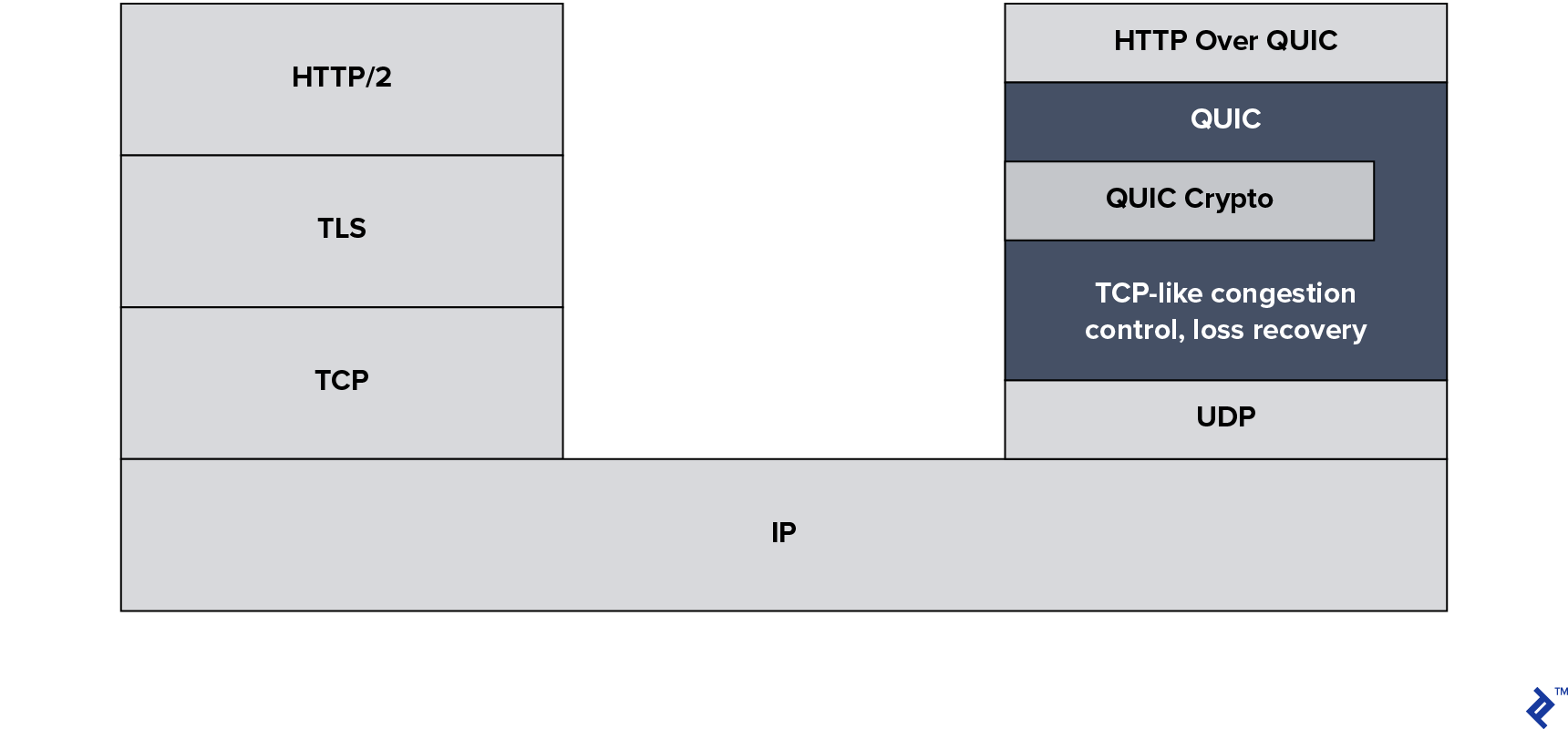
Note: There are many versions of QUIC, as the protocol has been in development and deployed in production environments for years. There’s even a Google-specific version called GQUIC. As such, it’s important to make a distinction between the old QUIC protocols and the new HTTP/3 standard.
Always Encrypted
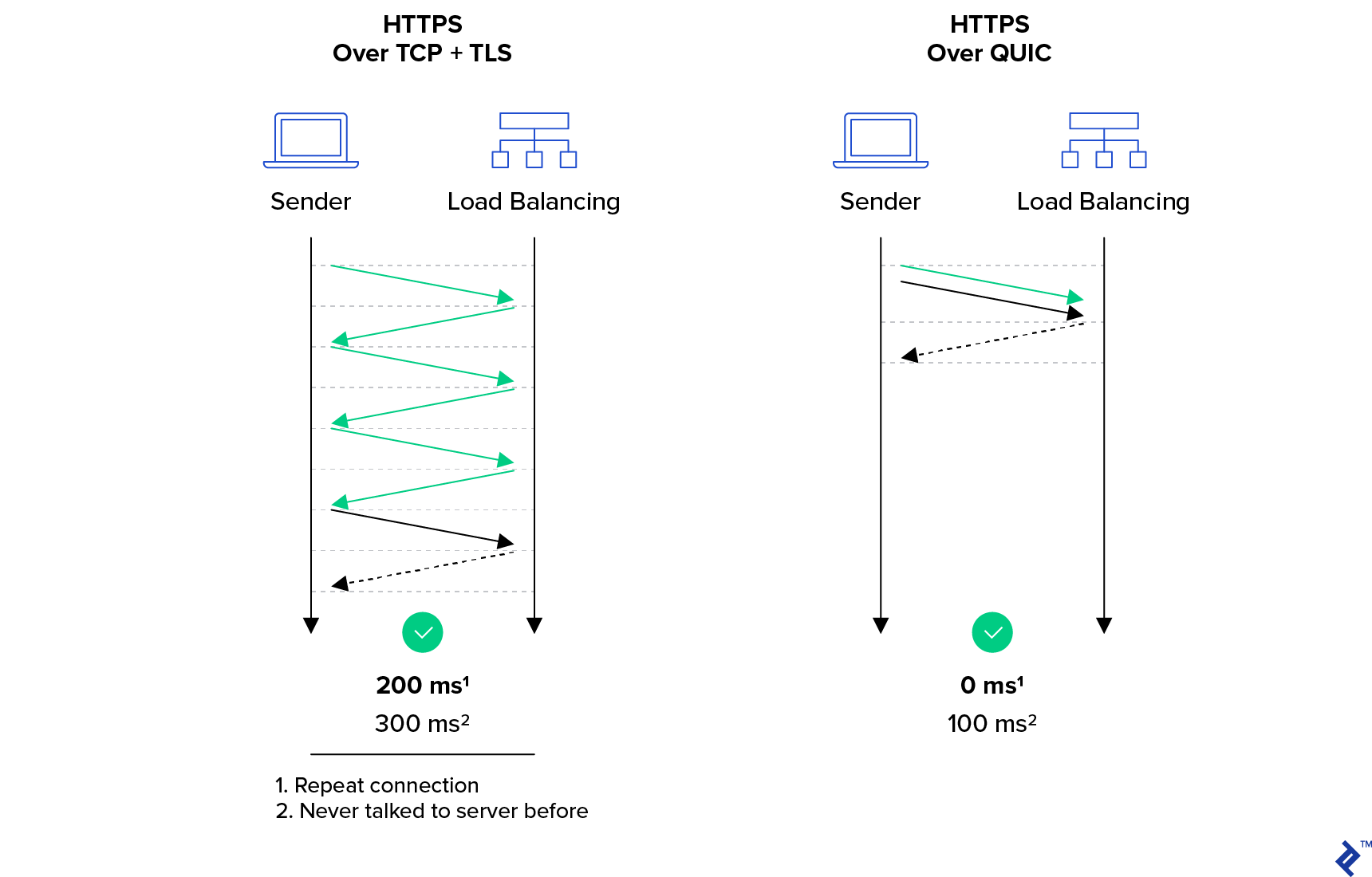
HTTP/3 includes encryption that borrows heavily from TLS but isn’t using it directly. One of the main implementation challenges for HTTP/3 is the TLS/SSL libraries needing to be modified to add the newly required functionality.
This change is because HTTP/3 differs from HTTPS in terms of what it encrypts. With the older HTTPS protocol, only the data itself is protected by TLS, leaving a lot of the transport metadata visible. In HTTP/3 both the data and the transport protocol are protected. This might sound like a security feature, and it is. But it’s done this way to avoid a lot of the overhead present in HTTP/2. Hence, encrypting the transport protocol as well as the data actually makes the protocol more performant.
HTTP/3’s Impact on Networking Infrastructure
HTTP/3 is not without controversy. The main concerns are about networking infrastructure.
Client-side HTTP/3
On the client side, it’s quite common for UDP traffic to be heavily rate-limited and/or blocked. Applying these restrictions to HTTP/3 defeats the point of the protocol.
Secondly, it’s quite common for HTTP to be monitored and/or intercepted. Even with HTTPS traffic, networks regularly watch the clear text transport elements of the protocol to determine if they should drop the connection for the purposes of preventing access to certain websites from specific networks or within specific regions. In some countries, this is even mandated by law for certain service providers. Mandatory encryption in HTTP/3 makes this impossible.
It’s not just government-level filtering. Many universities, public libraries, schools, and homes with concerned parents actively choose either to block access to certain websites or at least keep a log of which sites have been visited. Mandatory encryption in HTTP/3 makes this impossible.
It’s worth noting that limited filtering is currently possible. This is because the server name indication (SNI) field—which carries the hostname of the website but not path, query parameters, etc.—is still not encrypted. But this is set to change in the near future with the introduction of ESNI (encrypted SNI), which was recently added to the TLS standard.
Server-side HTTP/3
On the server side, it’s best practice to block any ports and protocols which aren’t expecting traffic, meaning that server administrators now need to open UDP 443 for HTTP/3, rather than relying on their existing TCP 443 rules.
Secondly, network infrastructure can make TCP sessions sticky, meaning that they will always be routed to the same server even as routing priorities change. As HTTP/3 runs over UDP—which is sessionless—network infrastructure needs to be updated to track HTTP/3-specific connection IDs, which have been left unencrypted specifically to aid in sticky routing.
Thirdly, it’s quite common for HTTP to be inspected to detect abuse, monitor for common security issues, detect and prevent the spread of malware and viruses, etc. This isn’t possible with HTTP/3 due to its encryption. Still, options where the intercepting device has a copy of the security keys are still possible, assuming the devices implement HTTP/3 support.
Finally, a lot of administrators object to having to manage even more SSL certificates, although that’s less of an issue now with services such as Let’s Encrypt being available.
Until there are widely accepted, well-known solutions to address these concerns, I think it’s likely a lot of big networks will simply block HTTP/3.
HTTP/3’s Impact on Web Development
There’s not much to worry about on this front. HTTP/2’s stream prioritization and server push features are still present in HTTP/3. It’s worth it for web developers to get familiar with these features if they want to really optimize their site performance.
Using HTTP/3 Right Now
Users of Google Chrome, or the open-source Chromium browser, are already set for using HTTP/3. Production-quality releases of HTTP/3 servers are still a little way off—the specification isn’t quite finalized as of this writing. But meanwhile there are plenty of tools to play with, and both Google and Cloudflare have already pushed support to their production environments.
The simplest way to try it out is by using Caddy in Docker. An SSL certificate is needed for this, so a publicly accessible IP address makes things easy. The steps are:
-
DNS setup. Get a working hostname that's live on the internet, e.g.
yourhostname.example.com IN A 192.0.2.1. - Caddyfile creation. It should contain these lines:
yourhostname.example.com
log stdout
errors stdout
ext .html .htm .md .txt
browse
gzip
tls youremailaddress@example.com
-
Running Caddy:
docker run -v Caddyfile:/etc/Caddyfile -p 80:80 -p 443:443 abiosoft/caddy --quic—or outside Docker,caddy --quic. -
Running chromium with QUIC enabled:
chromium --enable-quic - (Optional) Installing a Protocol Indicator extension.
- Navigating to the QUIC-enabled server, where a file browser should be visible.
Developers can also test their servers with the following useful tools:
- Keycdn’s HTTP/2 Test
- LiteSpeed’s HTTP3Check
- Qualys’ SSL Server Test
Thanks for reading!

Further Reading on the Toptal Blog:
Understanding the basics
How does HTTP/2 work?
HTTP/2 focuses on efficient bandwidth use to optimize the time required to deliver web content. Requests and responses are multiplexed over a single connection to allow for maximum throughput, with neither the client nor the server having to unnecessarily spend time waiting for each other.
What is the function of HTTP?
HTTP is a set of rules for making content available globally. The system created by HTTP is called the World Wide Web, or often just the Web. Using HTTP, web browsers are able to retrieve content from web servers. It is now also commonly used by servers to exchange content with other servers.
What is the difference between HTTP and HTTP/2?
HTTP/2 improves on older HTTP versions by introducing new features that use less bandwidth and speed up data transfer. The main difference between the protocols in terms of features is performance. In terms of technical design, the protocols hardly resemble each other and only share the original abstract concepts.
What is the purpose of the HTTP protocol?
The Hypertext Transfer Protocol (HTTP) allows for the publishing of content on a global scale via the Web. Although there are many other important uses, it is this global reach and generic purpose that has made HTTP a versatile and popular tool.
What kind of scheme is the HTTP protocol?
In a uniform resource locator (URL), the scheme is part before the colon which allows the reader to know how to interpret the rest of the URL. For web addresses, this is either HTTP or HTTPS. HTTPS is the secure encrypted variant of the HTTP protocol standard.
What is the TCP protocol used for?
TCP is used to establish a bidirectional first-in-first-out (FIFO) stream between two devices on the internet. Through this stream any data can reliably pass. As such, TCP is a building block for many other protocols, including those for the web (HTTP, HTTPS, and HTTP/2) and email (SMTP, POP, and IMAP).
What is TCP and how does it work?
TCP, often referred to as TCP/IP, is an abstraction mechanism that allows devices on the internet to communicate with each other in a reliable fashion, despite most of the internet’s infrastructure being very unreliable and stateless. TCP works by implementing stateful sessions and congestion control.
What causes head-of-line blocking in HTTP/2?
HTTP/2 uses TCP to ensure that there is a guaranteed reliable connection. In TCP, a recipient handles re-transmitted copies of lost data by reordering the received data and only releasing the newest data after releasing the preceding data. This waiting blocks the head of the line, which degrades performance.
What is the latest version of HTTP?
HTTP/3 is the latest version of HTTP. Although not officially released yet, HTTP/3 is already extensively deployed. Earlier versions of HTTP were released in 2015 (HTTP/2), 1999 (HTTP/1.1), 1997 (HTTP/1.0), and 1989 (HTTP/0.9).
London, United Kingdom
December 12, 2017
About the author
Brian was a system administrator and network engineer before turning to software development in an effort to automate himself out of a job.