Enhanced Git Flow Explained
Git provides basic branching operations, but advanced patterns are left up to the user. The popular “Git flow” branching model helps, but can also complicate some common procedures.
Thankfully, a new variation retains the benefits, while streamlining everyday work.

Git provides basic branching operations, but advanced patterns are left up to the user. The popular “Git flow” branching model helps, but can also complicate some common procedures.
Thankfully, a new variation retains the benefits, while streamlining everyday work.

Daniel has helped startups bring products to market for more than a decade using best-of-breed approaches to HTML/CSS, JS, Python, and C#.
PREVIOUSLY AT

Inadvertently causing damage with Git can be all too easy. Yet, the best way to use Git will always be controversial.
That’s because Git itself only details basic branching operations, which leaves its usage patterns—i.e., branching models—a matter of user opinion. Git branching models promise to ease the pain by organizing the chaos that inevitably arises as software developers make changes to their codebases.
Like many developers, you wanted something that would “just work” so you could get on with actual software development. So you picked up Git flow, a branching model often recommended to Git users. Maybe you were on board with Git flow’s logic at first, until you hit some snags with it in practice—wrestling with Git flow multiple release branches, working out Git flow staging options, etc. Or maybe Git flow doesn’t seem like a good enough fit for you to adopt it. After all, there are countless variables at play, and no single branching model will work well in every situation.
Good news! A variation of the classic Git flow model, enhanced Git flow simplifies the more common maneuvers of the Git flow workflow while still retaining the main advantages.
The Splendor and Misery of Classic Git Flow Explained
I’ve been a strong advocate of Git flow ever since I discovered how it excels when developing a product that evolves in significant value increments (in other words, releases).
A significant value increment requires a significant amount of time to complete, like the two-week-plus sprints typically used in Scrum-based development. If a development team has already deployed to production, there may be trouble if the scope of the next release accumulates at the same place where production code lives—e.g., in the main branch of the Git repo they use.
While the product is still in the initial development phase—i.e., there’s no production and there are no real users of the product—it’s okay for the team to simply keep everything inside the main branch. In fact, it’s more than okay: This strategy allows the fastest pace of development without much ceremony. But things change in a production environment; then, real people start to rely on the product to be stable.
For example, if there’s a critical bug in production that needs to be fixed immediately, it would be a major disaster for the development team to have to roll back all the work accrued in the main branch thus far just to deploy the fix. And deploying code without proper testing—whether the code is considered half-baked or well-developed—is clearly not an option.
That’s where branching models shine, including Git flow. Any sophisticated branching model should answer questions regarding how to isolate the next release from the version of the system currently used by people, how to update that version with the next release, and how to introduce hotfixes of any critical bugs to the current version.
The Git flow process addresses these fundamental scenarios by separating “main” (the production or “current version” branch) and “develop” (the development or “next release” branch) and providing all the rules about using feature/release/hotfix branches. It effectively solves a lot of headaches from the development workflows of release-based products.
But even with projects well-suited to the classic Git flow model, I’ve suffered the typical problems it can bring:
- Git flow is complex, with two long-lived branches, three types of temporary branches, and strict rules on how branches deal with each other. Such complexity makes mistakes more likely and increases the effort required to fix them.
- The Git flow release branch and hotfix branch types both require “double merging”—once into main, then into develop. At times you can forget to do both. You can make Git flow branching easier with scripts or VCS GUI client plugins, but you have to set them up first for every machine of every developer involved in a given project.
- In CI/CD workflows, you usually end up with two final builds for a release—one from the latest commit of the release branch itself and another one from the merge commit to main. Strictly speaking, you should use the one from the main, but the two are usually identical, creating the potential for confusion.
Enter “Enhanced Git Flow”
The first time I used enhanced Git flow was on a greenfield, closed-source project. I was working with one other developer, and we had been working on the project by committing directly to the main branch.
Note: Up until the first public release of a product, it absolutely makes sense to commit all changes directly to the main branch—even if you are a Git flow advocate—for the sake of the speed and simplicity of the development workflow. Since there’s no production yet, there’s no possibility of a production bug that the team needs to fix ASAP. Doing all the branching magic that classic Git flow implies is therefore overkill at this stage.
Then we got close to the initial release and we agreed that, beyond that point, we wouldn’t be comfortable anymore with committing directly to the main branch. We had moved pretty rapidly, and business priorities didn’t leave much room to establish a rock-solid development process—i.e., one with enough automated testing to give us the confidence that keep our main branch was in a release-ready state.
It seemed to be a valid case for the classic Git flow model. With separate main and develop branches and enough time between significant value increments, there was confidence that mostly manual QA would yield good enough results. When I advocated for Git flow, my colleague suggested something similar, but with some key differences.
At first, I pushed back. It seemed to me that some of the proposed “patches” to classic Git flow were a bit too revolutionary. I thought they might break the main idea, and the whole approach would fall short. But with further thought, I realized that these tweaks don’t actually break Git flow. Meanwhile, they make it a better Git branching model by resolving all the pain points mentioned above.
After success with the modified approach in that project, I’ve used it in another closed-source project with a small team behind it, where I was the permanent codebase owner and an outsourced developer or two helped from time to time. On this project, we went to production six months in, and since then, we’ve been using CI and E2E testing for over a year, with releases every month or so.
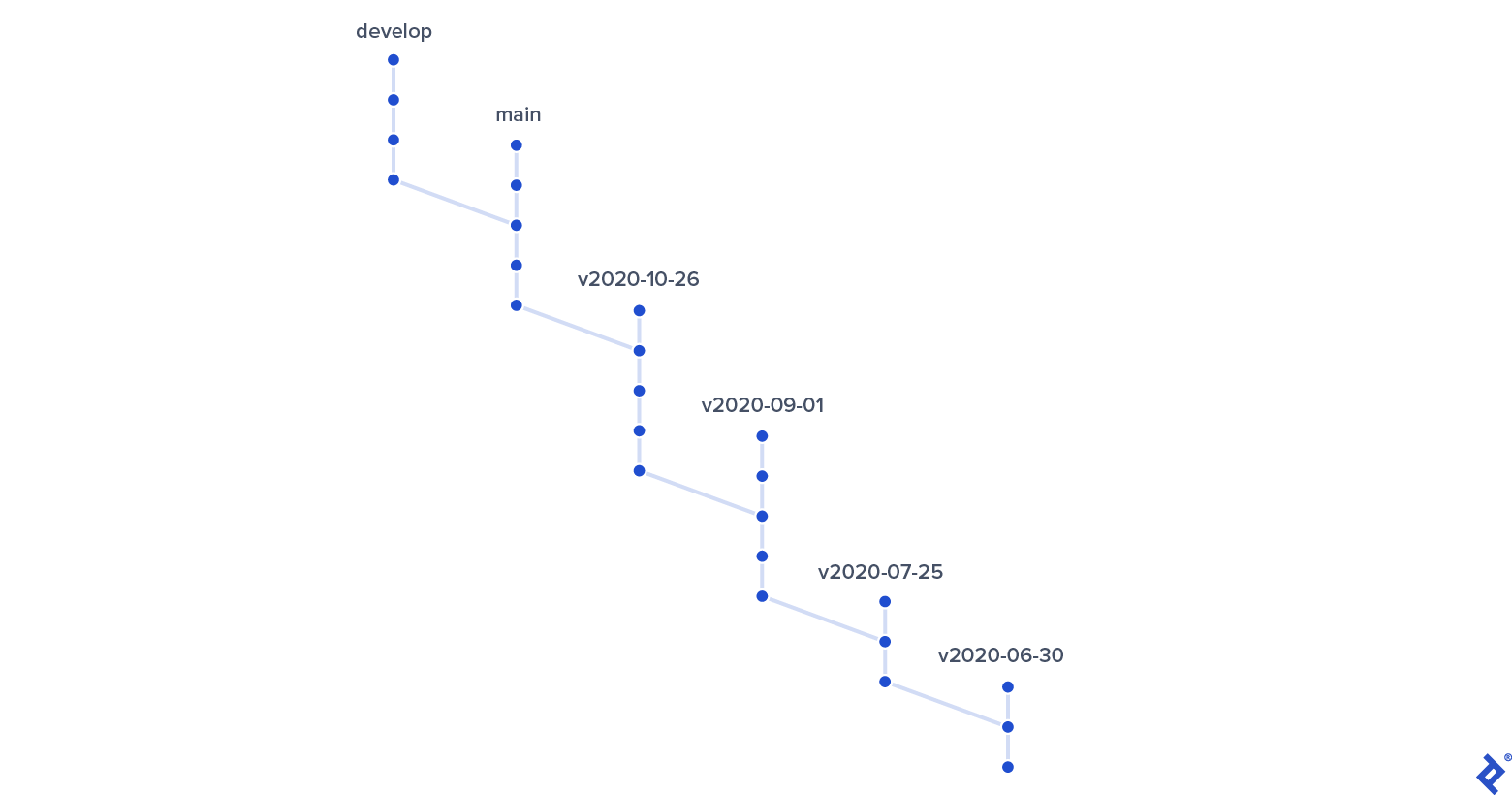
My overall experience with this new branching approach was so positive that I wanted to share it with my fellow developers to help them get around the drawbacks of classic Git flow.
Similarities to Classic Git Flow: Development Isolation
For work isolation in enhanced Git flow, there are still two long-lived branches, main and develop. (Users still have hotfix and release capabilities—with an emphasis on “capabilities,” since these aren’t branches anymore. We’ll get into details in the differences section.)
There’s no official naming scheme for classic Git flow feature branches. You just branch out from develop and merge back in to develop when the feature is ready. Teams can use any naming convention they’d like or simply hope that developers will use more descriptive names than “my-branch.” The same is true for enhanced Git flow.
All features accumulated in the develop branch up to some cut-off point will shape the new release.
Squash Merges
I strongly recommended using squash merge for feature branches to keep history nice and linear most of the time. Without it, commit graphs (from GUI tools or git log --graph) start to look sloppy when a team is juggling even a handful of feature branches:
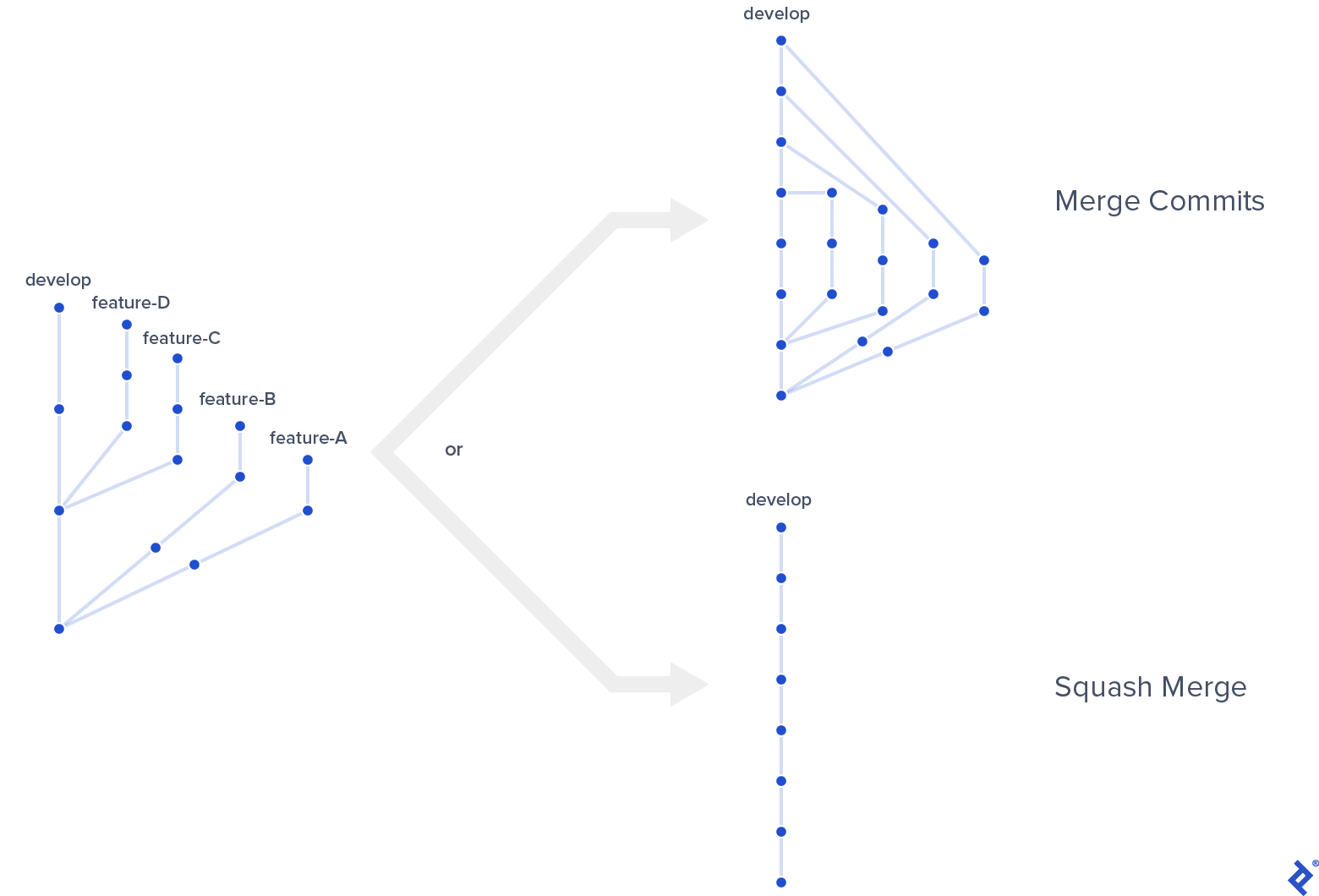
But even if you’re OK with the visuals in this scenario, there’s another reason to squash. Without squashing, commit history views—among them both plain git log (without --graph) and also GitHub—tell rather incoherent stories even with the simplest of merge scenarios:
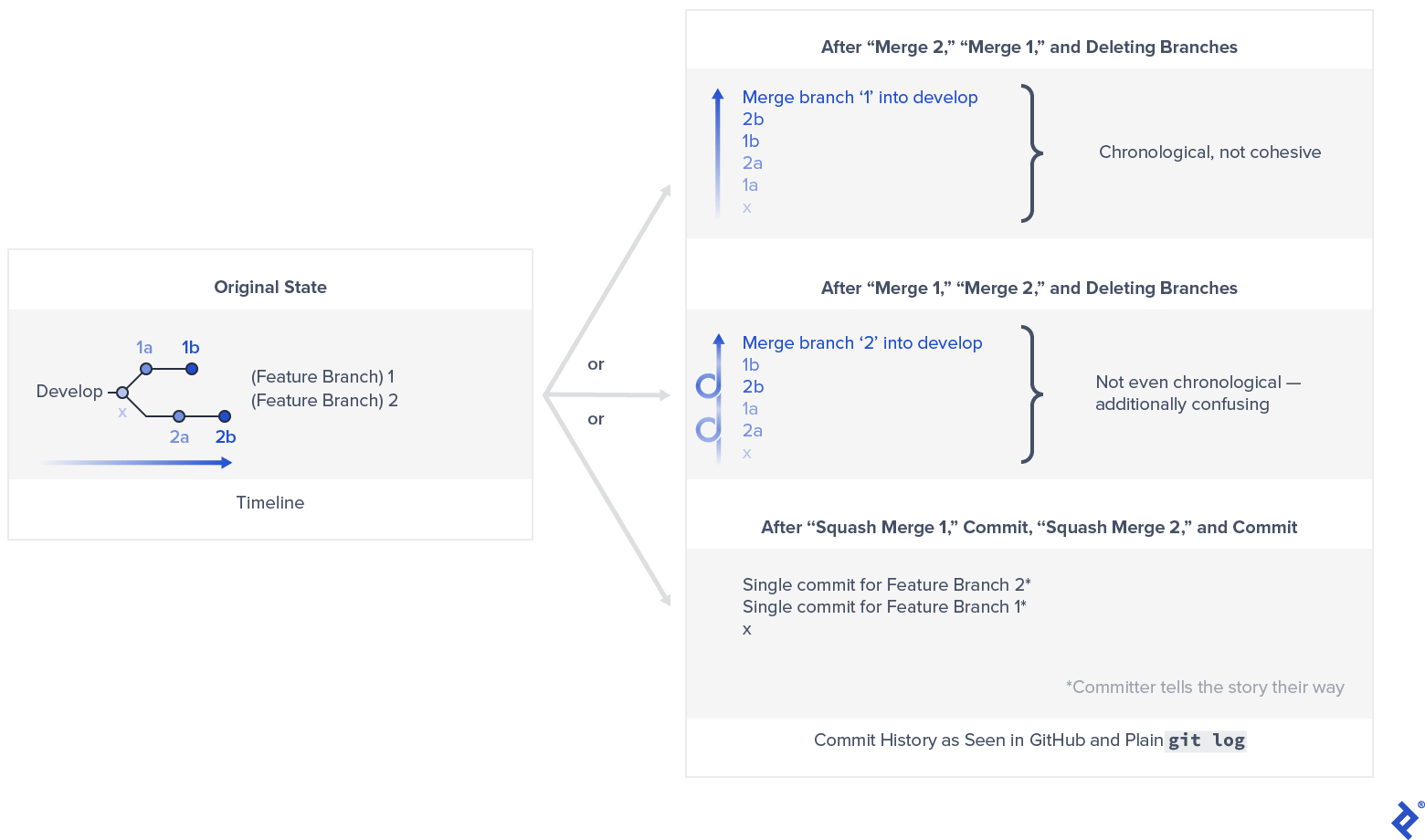
The caveat to using squash merging is that the original feature branch history gets lost. But this caveat doesn’t even apply if you’re using GitHub, for example, which exposes the full original history of a feature branch via the pull request that was squash merged, even after the feature branch itself gets deleted.
Differences from Classic Git Flow: Releases and Hotfixes
Let’s go through the release cycle as (hopefully) it’s the main thing you’ll be doing. When we get to the point where we’d like to release what’s accumulated in develop, it’s strictly a superset of main. After that is where the biggest differences between classic and enhanced Git flow begin.
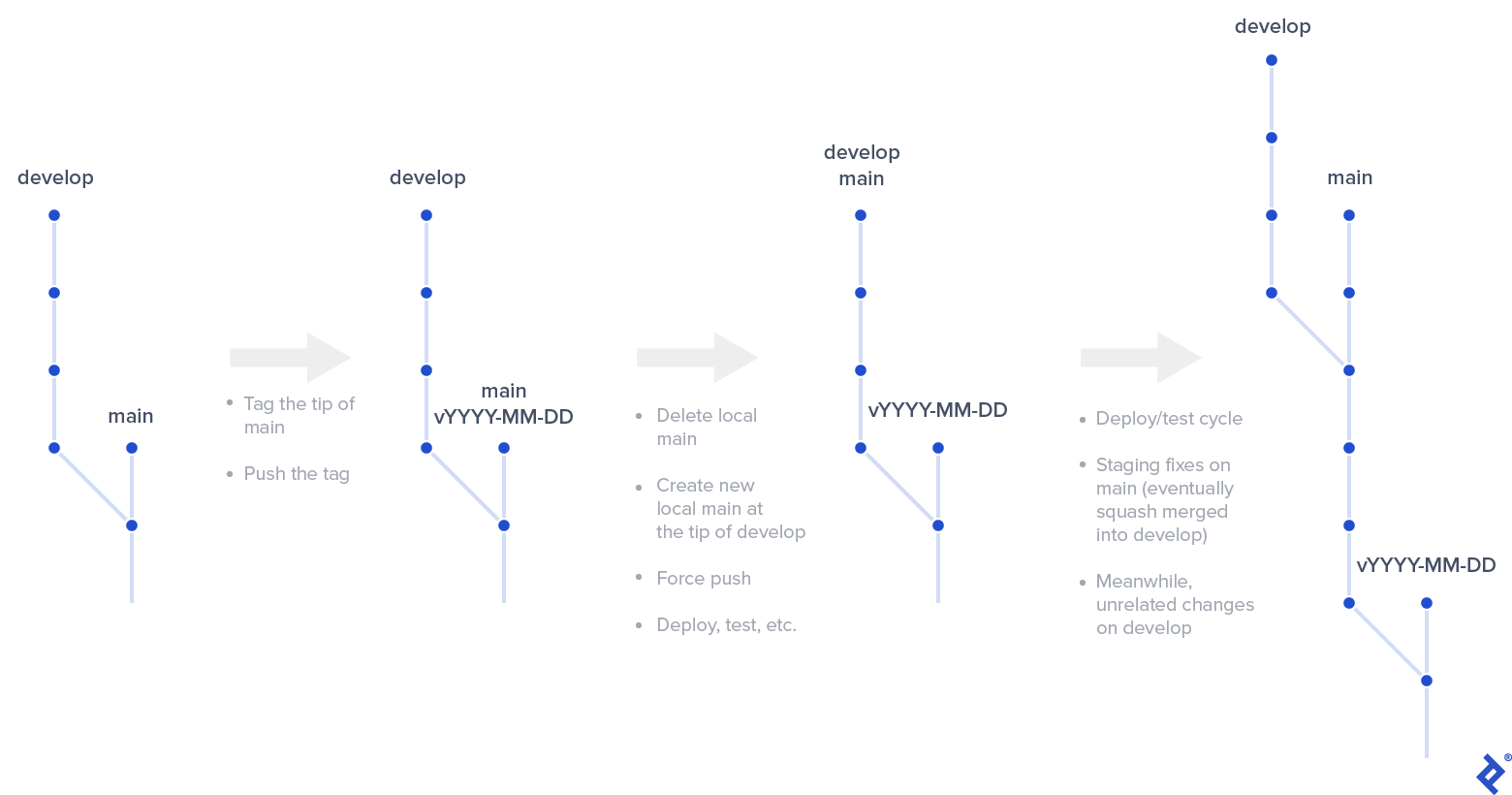
Releases in Enhanced Git Flow
Every step of making a release with enhanced Git flow differs from the classic Git flow process:
- Releases are based on main, rather than develop. Tag the current tip of the main branch with something meaningful. I adopted tags based on the current date in ISO 8601 format prefixed with a “v”—e.g., v2020-09-09.
- If there happened to be multiple releases in a day—for example, hotfixes—the format could have a sequential number or letter tacked onto it as needed.
- Be aware that the tags do not, in general, correspond to release dates. They’re solely to force Git to keep a reference to how the main branch looked at the time the next release process began.
-
Push the tag using
git push origin <the new tag name>. - After that, a bit of surprise: delete your local main branch. Don’t worry, because we’re going to restore it shortly.
- All of the commits to main are still safe—we protected them from garbage collection by tagging main on the previous step. Every one of these commits—even hotfixes, as we’ll cover shortly—is also part of development.
- Just make sure only one person on a team is doing this for any given release; that’s the so-called “release manager” role. A release manager is usually the most experienced and/or most senior team member, but a team would be wise to avoid any particular team member taking on this role permanently. It makes more sense to spread knowledge among the team to increase the infamous bus factor.
- Create a new local main branch at the tip commit of your develop branch.
-
Push this new structure using
git push --force, since the remote repo won’t accept such a “drastic change” so easily. Again, this isn’t as unsafe as it may seem in this context because:- We’re merely moving the main branch pointer from one commit to another.
- Only one particular team member is doing this change at a time.
- Everyday development work happens on the develop branch, so you won’t disrupt anyone’s work by moving main this way.
- (This is unlike the “Git flow without a develop branch” approach, where development happens directly on the main branch.)
- You have your new release! Deploy it to the staging environment and test it. (We’ll discuss convenient CI/CD patterns below.) Any fixes go directly to the main branch, and it’ll start to diverge from the develop branch because of that.
- At the same time, you can start to work on a new release in the develop branch, the same advantage seen in classic Git flow.
- In the unfortunate event that a hotfix is needed for what’s currently in production (not the upcoming release in staging) at this point, there are more details about this scenario in “Dealing with hotfixes during an active release…” below.
- When your new release is considered stable enough, deploy the final version to the production environment and do a single squash merge of main to develop to pick up all the fixes.
Hotfixes in Enhanced Git Flow
Hotfix cases are twofold. If you’re doing a hotfix when there’s no active release—i.e., the team is preparing a new release in the develop branch—it’s a breeze: Commit to main, get your changes deployed and tested in staging until they’re ready, then deploy to production.
As the last step, cherry-pick your commit from main to develop to ensure the next release will contain all the fixes. In case you end up with several hotfix commits, you save effort—especially if your IDE or other Git tool can facilitate it—by creating and applying a patch instead of cherry-picking multiple times. Trying to squash merge main to develop after the initial release is likely to end up with conflicts with the independent progress made in the develop branch, so I don’t recommend that.
Dealing with hotfixes during an active release—i.e., when you just force pushed main and are still preparing the new release—is the weakest part of enhanced Git flow. Depending on the length of your release cycle and severity of the issue you have to sort out, always aim to include fixes in the new release itself—that’s the easiest way to go, and won’t disrupt the overall workflow at all.
In case that’s a no-go—you have to introduce a fix quickly, and you can’t wait for the new release to get ready—then get ready for a somewhat intricate Git procedure:
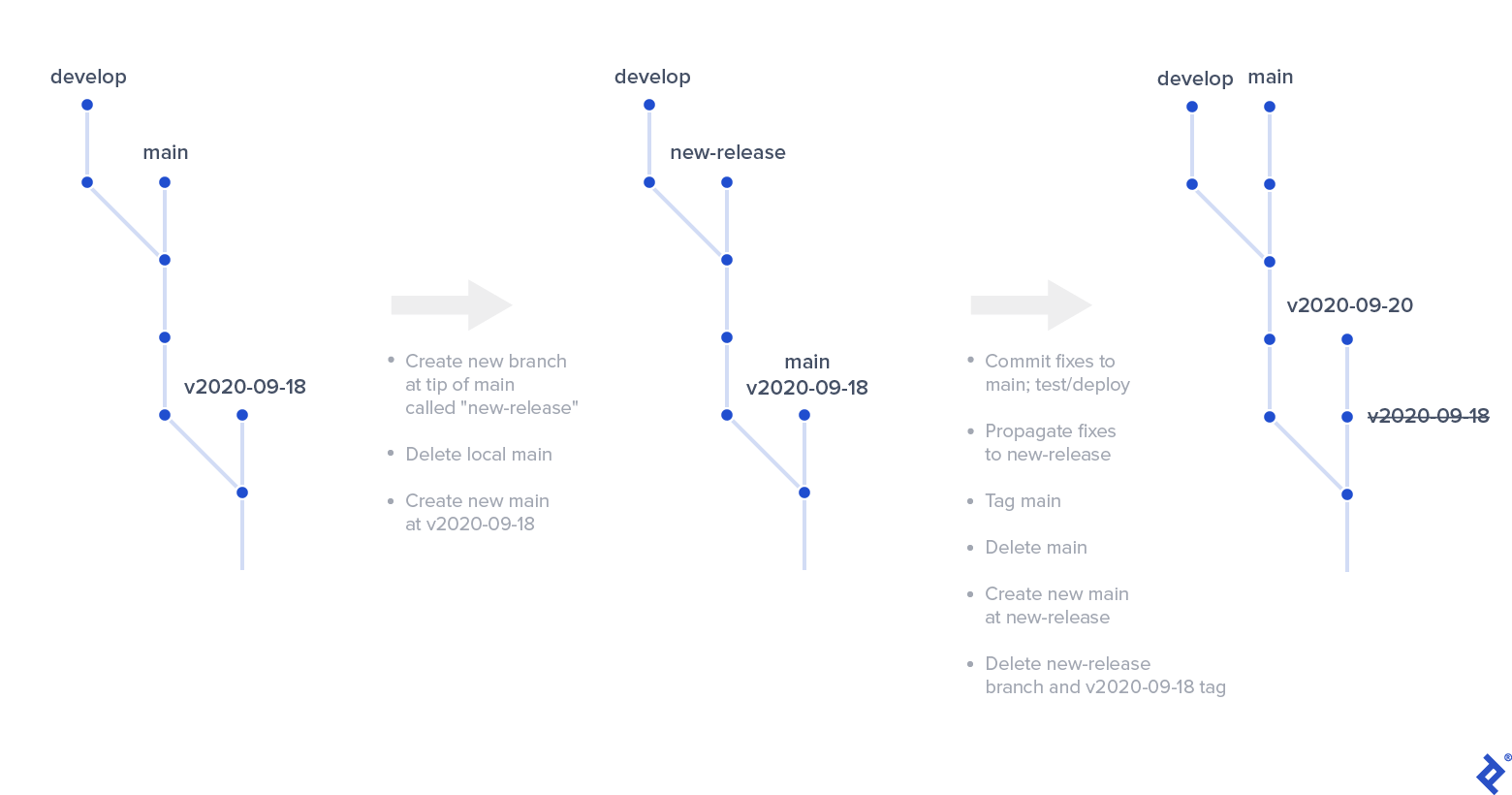
- Create a branch—we’ll call it “new-release,” but your team can adopt any naming convention here—at the same commit as the current tip of main. Push new-release.
- Delete and recreate the local main branch at the commit of the tag you created previously for the current active release. Force push main.
- Introduce the necessary fixes to main, deploy to the staging environment, and test. Whenever that’s ready, deploy to production.
- Propagate changes from the current main to new-release either via cherry-picking or a patch.
- After that, redo the release procedure: Tag the tip of the current main and push the tag, delete and recreate the local main at the tip of the new-release branch, and force push main.
- You likely won’t need the previous tag, so you can remove it.
- The new-release branch is now redundant, so you can remove it, too.
- You should now be good to go as usual with a new release. Finish up by propagating the emergency hotfixes from main to develop via cherry-picking or a patch.
With proper planning, high enough code quality, and a healthy development and QA culture, it’s unlikely your team will have to use this method. It was prudent to develop and test such a disaster plan for enhanced Git flow, just in case—but I’ve never needed to use it in practice.
CI/CD Setup on Top of Enhanced Git Flow
Not every project requires a dedicated development environment. It may be easy enough to set up a sophisticated local development environment on each developer machine.
But a dedicated development environment can contribute toward a healthier development culture. Running tests, measuring test coverage, and calculating complexity metrics on the develop branch often decreases the cost of mistakes by catching them well before they end up in staging.
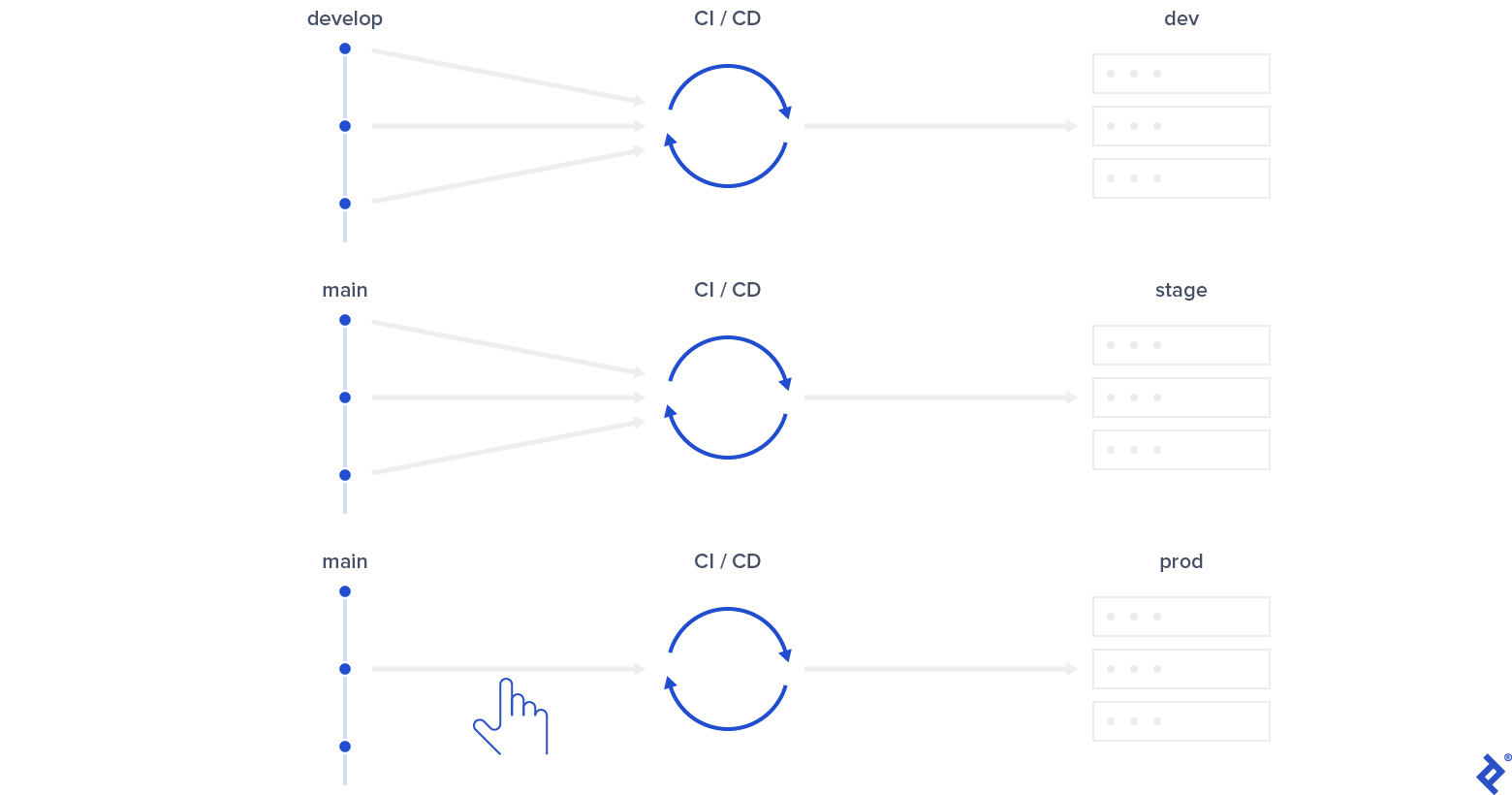
I found some CI/CD patterns to be especially useful when combined with enhanced Git flow:
- If you need a development environment, set up CI to build, test, and deploy to it upon each commit to the develop branch. Fit in E2E testing here also, if you have it and if it makes sense in your case.
- Set up CI to build, test, and deploy to the staging environment on each commit to the main branch. E2E testing is quite beneficial at this point, too.
- It may seem redundant to use E2E testing in both places, but remember that hotfixes won’t happen in develop. Triggering E2E on commits to main will test hotfixes and everyday changes before they go out, but also triggering on commits to develop will catch bugs earlier.
- Configure CI in a way that allows your team to deploy builds from main to the production environment upon a manual request.
Such patterns are relatively simple, yet provide powerful machinery to support day-to-day development operations.
The Enhanced Git Flow Model: Improvements and Possible Limitations
Enhanced Git flow is not for everyone. It does leverage the controversial tactic of force pushing the main branch, so purists may resent it. From a practical standpoint, there’s nothing wrong with it, though.
As mentioned, hotfixes are more challenging during a release but still possible. With proper attention to QA, test coverage, etc. that shouldn’t happen too often, so from my perspective, it’s a valid trade-off for the overall benefits of enhanced Git flow in comparison to classic Git flow. I would be very interested to hear how enhanced Git flow fares in larger teams and with more complex projects, where hotfixes may be a more frequent occurrence.
My positive experience with the enhanced Git flow model also revolves mostly around closed-source commercial projects. It may be problematic for an open-source project where pull-requests are often based on an old release derivation of the source tree. There are no technical roadblocks to sort that out—it just might require more effort than expected. I welcome feedback from readers with a lot of experience in the open source space regarding the applicability of enhanced Git flow in such cases.
Special thanks to Toptal colleague Antoine Pham for his key role in developing the idea behind enhanced Git flow.

As a Microsoft Gold Partner, Toptal is your elite network of Microsoft experts. Build high-performing teams with the experts you need - anywhere and exactly when you need them!
Further Reading on the Toptal Blog:
Understanding the basics
What is Git flow?
Git flow is a branching model for the Git version control system (VCS). A branching model builds on basic Git operations, prescribing usage patterns meant to enable robust version management. Git flow was publicly announced in a blog article by Vincent Driessen in 2010 and has remained popular ever since.
What is the Git flow branching strategy?
The Git flow branching strategy excels when developing a product that evolves in significant value increments. It does so by separating “main” (the production or “current version” branch) and “develop” (the development or “next release” branch) and providing all the necessary rules about using helper branches.
How do I use Git flow?
You use Git flow by following its prescribed pattern. This lets your team get answer questions about how to isolate the next release from the version of the system currently in production, how to update that version with the next release, and how to introduce hotfixes of any critical bugs to the current version.
Should I use Git flow?
Whether you should use Git flow or not depends on your particular project. The main question to answer is, “Does the overall development workflow have enough automatic quality assurance to keep the main branch in release-ready state?” If the answer is no, then such a project will likely benefit from Git flow.
What is the best Git workflow?
There’s no single best Git workflow, because the answer depends on the particular project context. Some projects will benefit from Git flow or a variation of it, while others will be better with a trunk-based development approach.
Daniel Ivanov
Moscow, Russia
July 6, 2016
About the author
Daniel has helped startups bring products to market for more than a decade using best-of-breed approaches to HTML/CSS, JS, Python, and C#.
PREVIOUSLY AT