Deploy Web Applications Automatically Using GitHub Webhooks
Deploying instances of a web application to one or more servers manually can often be a monotonous process, and take up a significant amount of your time. With little effort, it is possible to automate the process of deploying your web application with almost zero human intervention. This article outlines a simple approach to automating web application deployments using GitHub webhooks, buildpacks, and Procfiles.

Deploying instances of a web application to one or more servers manually can often be a monotonous process, and take up a significant amount of your time. With little effort, it is possible to automate the process of deploying your web application with almost zero human intervention. This article outlines a simple approach to automating web application deployments using GitHub webhooks, buildpacks, and Procfiles.

Mahmud is a software developer with many years of experience and a knack for efficiency, scalability, and stable solutions.
Anyone who develops web applications and attempts to run them on their own unmanaged servers is aware of the tedious process involved with deploying their application and pushing future updates. Platform as a service (PaaS) providers have made it easy to deploy web applications without having to go through the process of provisioning and configuring individual servers, in exchange for a slight increase in costs and decrease in flexibility. PaaS may have made things easier, but sometimes we still need to or want to deploy applications on our own unmanaged servers. Automating this process of deploying web applications to your server may sound overwhelming at first, but in reality coming up with a simple tool to automate this may be easier than you think. How easy it is going to be to implement this tool depends a lot on how simple your needs are, but it certainly is not difficult to achieve, and can probably help save a lot of time and effort by doing the tedious repetitive bits of web application deployments.
Many developers have come up with their own ways of automating the deployment processes of their web applications. Since how you deploy your web applications depends a lot on the exact technology stack being used, these automation solutions vary between one another. For example, the steps involved in automatically deploying a PHP website is different from deploying a Node.js web application. Other solutions exist, such as Dokku, that are pretty generic and these things (called buildpacks) work well with a wider range of technology stack.

In this tutorial, we will take a look at the fundamental ideas behind a simple tool that you can build to automate your web application deployments using GitHub webhooks, buildpacks, and Procfiles. The source code of the prototype program that we will explore in this article is available on GitHub.
Getting Started with the Web Applications
To automate deployment of our web application, we will write a simple Go program. If you are unfamiliar with Go, do not hesitate to follow along, as the code constructs used throughout this article are fairly simple and should be easy to understand. If you feel like it, you can probably port the entire program into a language of your choice quite easily.
Before starting, make sure you have the Go distribution installed on your system. To install Go, you can follow the steps outlined in the official documentation.
Next, you can download the source code of this tool by cloning the GitHub repository. This should make it easy for you to follow along as the code snippets in this article are labelled with their corresponding file names. If you want to, you can try it out right away.
One major advantage of using Go for this program is that we can build it in a way where we have minimal external dependencies. In our case, to run this program on a server we just need to ensure that we have Git and Bash installed. Since Go programs are compiled into statically linked binaries, you can compile the program on your computer, upload it to the server, and run it with almost zero effort. For most other popular languages of today, this would require some mammoth runtime environment or interpreter installed on the server just to run your deployment automator. Go programs, when done right, can also be very easy going on CPU and RAM - which is something you want from programs like this.
GitHub Webhooks
With GitHub Webhooks, it is possible to configure your GitHub repository to emit events every time something changes within the repository or some user performs particular actions on the hosted repository. This allows users to subscribe to these events and be notified through URL invocations of the various events that take place around your repository.
Creating a webhook is very simple:
- Navigate to the settings page of your repository
- Click on “Webhooks & Services” on the left nav menu
- Click on the “Add webhook” button
- Set a URL, and optionally a secret (which will allow the recipient to verify the payload)
- Make other choices on the form, as necessary
- Submit the form by clicking on the green “Add webhook” button
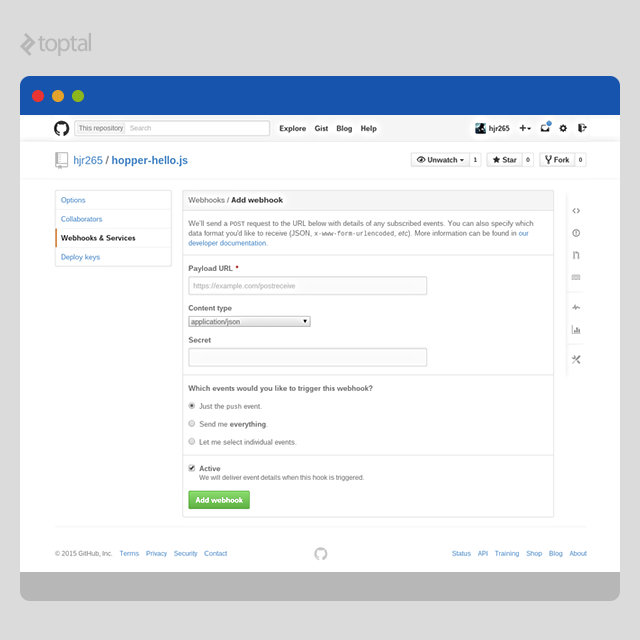
GitHub provides extensive documentation on Webhooks and how exactly they work, what information is delivered in the payload in response to various events, etc. For the purpose of this article, we are particularly interested in the “push” event which is emitted every time someone pushes to any repository branch.
Buildpacks
Buildpacks are pretty much standard these days. Used by many PaaS providers, buildpacks allow you to specify how the stack will be configured before an application is deployed. Writing buildpacks for your web application is really easy, but more often than not a quick search on the web can find you a buildpack that you can use for your web application without any modification.
If you have deployed application to PaaS like Heroku, you may already know what buildpacks are and where to find them. Heroku has some comprehensive documentation about the structure of buildpacks, and a list of some well built popular buildpacks.
Our automation program will use compile script to prepare the application before launching it. For example, a Node.js build by Heroku parses the package.json file, downloads an appropriate version of Node.js, and downloads NPM dependencies for the application. It is worth noting that to keep things simple, we will not have extensive support for buildpacks in our prototype program. For now, we will assume that buildpack scripts are written to be run with Bash, and that they will run on a fresh Ubuntu installation as it is. If necessary, you can easily extend this in the future to address more esoteric needs.
Procfiles
Procfiles are simple text files that allow you to define the various types of processes that you have in your application. For most simple applications, you would ideally have a single “web” process which would be the process that handles HTTP requests.
Writing Procfiles is easy. Define one process type per line by typing its name, followed by a colon, followed by the command that will spawn the process:
<type>: <command>
For example, if you were working with a Node.js based web application, to start the web server you would execute the command “node index.js”. You can simply create a Procfile at the base directory of the code and name it “Procfile” with the following:
web: node index.js
We will require applications to define process types in Procfiles so that we can start them automatically after pulling in the code.
Handling Events
Within our program, we must include an HTTP server that will allow us to receive incoming POST requests from GitHub. We will need to dedicate some URL path to handle these requests from GitHub. The function that will handle these incoming payloads will look something like this:
// hook.go
type HookOptions struct {
App *App
Secret string
}
func NewHookHandler(o *HookOptions) http.Handler {
return http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {
evName := r.Header.Get("X-Github-Event")
if evName != "push" {
log.Printf("Ignoring '%s' event", evName)
return
}
body, err := ioutil.ReadAll(r.Body)
if err != nil {
http.Error(w, "Internal Server Error", http.StatusInternalServerError)
return
}
if o.Secret != "" {
ok := false
for _, sig := range strings.Fields(r.Header.Get("X-Hub-Signature")) {
if !strings.HasPrefix(sig, "sha1=") {
continue
}
sig = strings.TrimPrefix(sig, "sha1=")
mac := hmac.New(sha1.New, []byte(o.Secret))
mac.Write(body)
if sig == hex.EncodeToString(mac.Sum(nil)) {
ok = true
break
}
}
if !ok {
log.Printf("Ignoring '%s' event with incorrect signature", evName)
return
}
}
ev := github.PushEvent{}
err = json.Unmarshal(body, &ev)
if err != nil {
log.Printf("Ignoring '%s' event with invalid payload", evName)
http.Error(w, "Bad Request", http.StatusBadRequest)
return
}
if ev.Repo.FullName == nil || *ev.Repo.FullName != o.App.Repo {
log.Printf("Ignoring '%s' event with incorrect repository name", evName)
http.Error(w, "Bad Request", http.StatusBadRequest)
return
}
log.Printf("Handling '%s' event for %s", evName, o.App.Repo)
err = o.App.Update()
if err != nil {
return
}
})
}
We begin by verifying the type of event that has generated this payload. Since we are only interested in the “push” event, we can ignore all other events. Even if you configure the webhook to only emit “push” events, there will still be at least one other kind of event that you can expect to receive at your hook endpoint: “ping”. The purpose of this event is to determine if the webhook has been configured successfully on GitHub.
Next, we read the entire body of the incoming request, compute its HMAC-SHA1 using the same secret that we will use to configure our webhook, and determine the validity of the incoming payload by comparing it with the signature included in the header of the request. In our program, we ignore this validation step if the secret is not configured. On a side note, it may not be a wise idea to read the entire body without at least having some sort of upper limit on how much data we will want to deal with here, but let us keep things simple to focus on the critical aspects of this tool.
Then we use a struct from the GitHub client library for Go to unmarshal the incoming payload. Since we know it is a “push” event, we can use the PushEvent struct. We then use the standard json encoding library to unmarshal the payload into an instance of the struct. We perform a couple of sanity checks, and if all is okay, we invoke the function that starts updating our application.
Updating Application
Once we receive an event notification at our webhook endpoint, we can begin updating our application. In this article, we will take a look at a fairly simple implementation of this mechanism, and there will certainly be room for improvements. However, it should be something that will get us started with some basic automated deployment process.
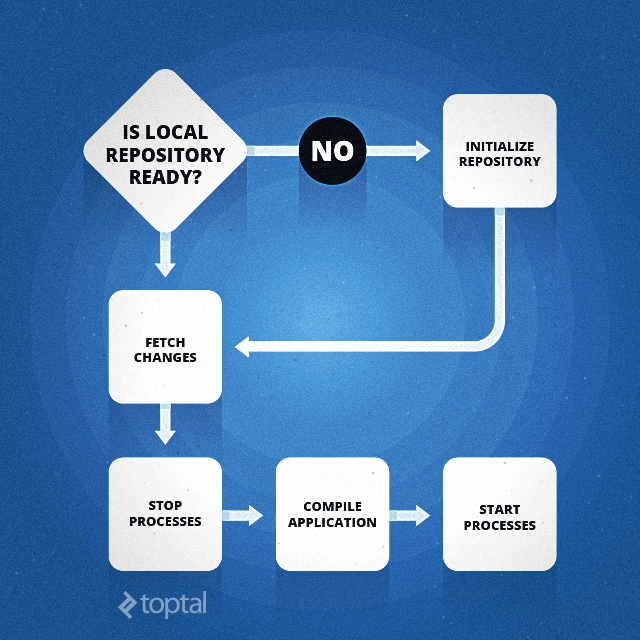
Initializing Local Repository
This process will begin with a simple check to determine if this is the first time we are trying to deploy the application. We will do so by checking if the local repository directory exists. If it doesn’t exist, we will initialize our local repository first:
// app.go
func (a *App) initRepo() error {
log.Print("Initializing repository")
err := os.MkdirAll(a.repoDir, 0755)
// Check err
cmd := exec.Command("git", "--git-dir="+a.repoDir, "init")
cmd.Stderr = os.Stderr
err = cmd.Run()
// Check err
cmd = exec.Command("git", "--git-dir="+a.repoDir, "remote", "add", "origin", fmt.Sprintf("git@github.com:%s.git", a.Repo))
cmd.Stderr = os.Stderr
err = cmd.Run()
// Check err
return nil
}
This method on the App struct can be used to initialize the local repository, and its mechanisms are extremely simple:
- Create a directory for the local repository if it doesn’t exist.
- Use the “git init” command to create a bare repository.
- Add a URL for the remote repository to our local repository, and name it “origin”.
Once we have an initialized repository, fetching changes should be simple.
Fetching Changes
To fetch changes from the remote repository, we just need to invoke one command:
// app.go
func (a *App) fetchChanges() error {
log.Print("Fetching changes")
cmd := exec.Command("git", "--git-dir="+a.repoDir, "fetch", "-f", "origin", "master:master")
cmd.Stderr = os.Stderr
return cmd.Run()
}
By doing a “git fetch” for our local repository in this manner, we can avoid issues with Git not being able to fast-forward in certain scenarios. Not that forced fetches are something you should rely on, but if you need to do a force push to your remote repository, this will handle it with grace.
Compiling Application
Since we are using scripts from buildpacks to compile our applications that are being deployed, our task here is a relatively easy one:
// app.go
func (a *App) compileApp() error {
log.Print("Compiling application")
_, err := os.Stat(a.appDir)
if !os.IsNotExist(err) {
err = os.RemoveAll(a.appDir)
// Check err
}
err = os.MkdirAll(a.appDir, 0755)
// Check err
cmd := exec.Command("git", "--git-dir="+a.repoDir, "--work-tree="+a.appDir, "checkout", "-f", "master")
cmd.Dir = a.appDir
cmd.Stderr = os.Stderr
err = cmd.Run()
// Check err
buildpackDir, err := filepath.Abs("buildpack")
// Check err
cmd = exec.Command("bash", filepath.Join(buildpackDir, "bin", "detect"), a.appDir)
cmd.Dir = buildpackDir
cmd.Stderr = os.Stderr
err = cmd.Run()
// Check err
cacheDir, err := filepath.Abs("cache")
// Check err
err = os.MkdirAll(cacheDir, 0755)
// Check err
cmd = exec.Command("bash", filepath.Join(buildpackDir, "bin", "compile"), a.appDir, cacheDir)
cmd.Dir = a.appDir
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
return cmd.Run()
}
We start by removing our previous application directory (if any). Next, we create a new one and checkout the contents of the master branch to it. We then use the “detect” script from the configured buildpack to determine if the application is something we can handle. Then, we create a “cache” directory for the buildpack compilation process if needed. Since this directory persists across builds, it may happen that we do not have to create a new directory because one will already exist from some previous compilation process. At this point, we can invoke the “compile” script from the buildpack and have it prepare everything necessary for the application before launch. When buildpacks are run properly, they can handle the caching and reuse of previously cached resources on their own.
Restarting Application
In our implementation of this automated deployment process, we are going to stop the old processes before we start the compilation process, and then start the new processes once the compilation phase is complete. Although this makes it easy to implement the tool, it leaves some potentially amazing ways of improving the automated deployment process. To improve on this prototype, you can probably start by ensuring zero downtime during updates. For now, we will continue with the simpler approach:
// app.go
func (a *App) stopProcs() error {
log.Print(".. stopping processes")
for _, n := range a.nodes {
err := n.Stop()
if err != nil {
return err
}
}
return nil
}
func (a *App) startProcs() error {
log.Print("Starting processes")
err := a.readProcfile()
if err != nil {
return err
}
for _, n := range a.nodes {
err = n.Start()
if err != nil {
return err
}
}
return nil
}
In our prototype, we stop and start the various processes by iterating over an array of nodes, where each node is a process corresponding to one of the instances of the application (as configured before launching this tool on the server). Within our tool, we keep track of the current state of the process for each node. We also maintain individual log files for them. Before all the nodes are started, each is assigned a unique port starting from a given port number:
// node.go
func NewNode(app *App, name string, no int, port int) (*Node, error) {
logFile, err := os.OpenFile(filepath.Join(app.logsDir, fmt.Sprintf("%s.%d.txt", name, no)), os.O_RDWR|os.O_CREATE|os.O_APPEND, 0666)
if err != nil {
return nil, err
}
n := &Node{
App: app,
Name: name,
No: no,
Port: port,
stateCh: make(chan NextState),
logFile: logFile,
}
go func() {
for {
next := <-n.stateCh
if n.State == next.State {
if next.doneCh != nil {
close(next.doneCh)
}
continue
}
switch next.State {
case StateUp:
log.Printf("Starting process %s.%d", n.Name, n.No)
cmd := exec.Command("bash", "-c", "for f in .profile.d/*; do source $f; done; "+n.Cmd)
cmd.Env = append(cmd.Env, fmt.Sprintf("HOME=%s", n.App.appDir))
cmd.Env = append(cmd.Env, fmt.Sprintf("PORT=%d", n.Port))
cmd.Env = append(cmd.Env, n.App.Env...)
cmd.Dir = n.App.appDir
cmd.Stdout = n.logFile
cmd.Stderr = n.logFile
err := cmd.Start()
if err != nil {
log.Printf("Process %s.%d exited", n.Name, n.No)
n.State = StateUp
} else {
n.Process = cmd.Process
n.State = StateUp
}
if next.doneCh != nil {
close(next.doneCh)
}
go func() {
err := cmd.Wait()
if err != nil {
log.Printf("Process %s.%d exited", n.Name, n.No)
n.stateCh <- NextState{
State: StateDown,
}
}
}()
case StateDown:
log.Printf("Stopping process %s.%d", n.Name, n.No)
if n.Process != nil {
n.Process.Kill()
n.Process = nil
}
n.State = StateDown
if next.doneCh != nil {
close(next.doneCh)
}
}
}
}()
return n, nil
}
func (n *Node) Start() error {
n.stateCh <- NextState{
State: StateUp,
}
return nil
}
func (n *Node) Stop() error {
doneCh := make(chan int)
n.stateCh <- NextState{
State: StateDown,
doneCh: doneCh,
}
<-doneCh
return nil
}
At a glance, this may seem a little more complicated than what we have done so far. To make things easy to grasp, let us break down the code above into four parts. The first two are within the “NewNode” function. When called, it populates an instance of the “Node” struct and spawns a Go routine that helps start and stop the process corresponding to this Node. The other two are the two methods on “Node” struct: “Start” and “Stop”. A process is started or stopped by passing a “message” through a particular channel that this per-node Go routine is keeping a watch on. You can either pass a message to start the process or a different message to stop it. Since the actual steps involved in starting or stopping a process happens in a single Go routine, there is no chance of getting race conditions.
The Go routine starts an infinite loop where it waits for a “message” through the “stateCh” channel. If the message passed to this channel requests the node to start the process (inside “case StateUp”), it uses Bash to execute the command. While doing that, it configures the command to use the user defined environment variables. It also redirects standard output and error streams to a pre-defined log file.
On the other hand, to stop a process (inside “case StateDown”), it simply kills it. This is where you could probably get creative, and instead of killing the process immediately send it a SIGTERM and wait a few seconds before actually killing it, giving the process a chance to stop gracefully.
The “Start” and “Stop” methods make it easy to pass the appropriate message to the channel. Unlike the “Start” method, the “Stop” method actually waits for the processes to be to killed before returning. “Start” simply passes a message to the channel to start the process and returns.
Combining It All
Finally, all that we need to do is wire everything up within the main function of the program. This is where we will load and parse the configuration file, update the buildpack, attempt to update our application once, and start the web server to listen for incoming “push” event payloads from GitHub:
// main.go
func main() {
cfg, err := toml.LoadFile("config.tml")
catch(err)
url, ok := cfg.Get("buildpack.url").(string)
if !ok {
log.Fatal("buildpack.url not defined")
}
err = UpdateBuildpack(url)
catch(err)
// Read configuration options into variables repo (string), env ([]string) and procs (map[string]int)
// ...
app, err := NewApp(repo, env, procs)
catch(err)
err = app.Update()
catch(err)
secret, _ := cfg.Get("hook.secret").(string)
http.Handle("/hook", NewHookHandler(&HookOptions{
App: app,
Secret: secret,
}))
addr, ok := cfg.Get("core.addr").(string)
if !ok {
log.Fatal("core.addr not defined")
}
err = http.ListenAndServe(addr, nil)
catch(err)
}
Since we require buildpacks to be simple Git repositories, “UpdateBuildpack” (implemented in buildpack.go) merely performs a “git clone” and a “git pull” as necessary with the repository URL to update the local copy of the buildpack.
Trying It Out
In case you have not cloned the repository yet, you can do it now. If you have the Go distribution installed, it should be possible to compile the program right away.
mkdir hopper
cd hopper
export GOPATH=`pwd`
go get github.com/hjr265/toptal-hopper
go install github.com/hjr265/toptal-hopper
This sequence of commands will create a directory named hopper, set it as GOPATH, fetch the code from GitHub along with the necessary Go libraries, and compile the program into a binary which you can find in the “$GOPATH/bin” directory. Before we can use this on a server, we need to create a simple web application to test this with. For convenience, I have created a simple “Hello, world”-like Node.js web application and uploaded it to another GitHub repository which you can fork and reuse for this test. Next, we need to upload the compiled binary to a server and create a configuration file in the same directory:
# config.tml
[core]
addr = ":26590"
[buildpack]
url = "https://github.com/heroku/heroku-buildpack-nodejs.git"
[app]
repo = "hjr265/hopper-hello.js"
[app.env]
GREETING = "Hello"
[app.procs]
web = 1
[hook]
secret = ""
The first option in our configuration file, “core.addr” is what lets us configure the HTTP port of our program’s internal web server. In the example above, we have set it to “:26590”, which will make the program listen for “push” event payloads at “http://{host}:26590/hook”. When setting up the GitHub webhook, just replace “{host}” with the domain name or IP address that points to your server. Make sure the port is open in case you are using some sort of firewall.
Next, we pick a buildpack by setting its Git URL. Here we are using Heroku’s Node.js buildpack.
Under “app”, we set “repo” to the full name of your GitHub repository hosting the application code. Since I am hosting the example application at “https://github.com/hjr265/hopper-hello.js”, the full name of the repository is “hjr265/hopper-hello.js”.
Then we set some environment variables for the application, and the number of each type of processes we need. And finally, we pick a secret, so that we can verify incoming “push” event payloads.
We can now start our automation program on the server. If everything is configured correctly (including deploy SSH keys, so that the repository is accessible from the server), the program should fetch the code, prepare the environment using the buildpack, and launch the application. Now all we need to do is setup a webhook in the GitHub repository to emit push events and point it to “http://{host}:26590/hook”. Make sure you replace “{host}” with the domain name or IP address that points to your server.
To finally test it, make some changes to the example application and push them to GitHub. You will notice that the automation tool will immediately get in action and update the repository on the server, compile the application, and restart it.
Conclusion
From most of our experiences, we can tell that this is something quite useful. The prototype application that we have prepared in this article may not be something that you will want to use on a production system as it is. There is a ton of room for improvement. A tool like this should have better error handling, support graceful shutdowns/restarts, and you may want to use something like Docker to contain the processes instead of directly running them. It may be wiser to figure out what exactly you need for your specific case, and come up with an automation program for that. Or perhaps use some other, much more stable, time-tested solution available all over the Internet. But in case you want to roll out something very customized, I hope this article will help you do that and show how much time and effort you could possibly save in the long run by automating your web application deployment process.
Dhaka, Dhaka Division, Bangladesh
January 16, 2014
About the author
Mahmud is a software developer with many years of experience and a knack for efficiency, scalability, and stable solutions.