Choosing a Tech Stack Alternative - The Ups and Downs
If a web application is big and old enough, there may come a time when you need to break it down into smaller, isolated parts and extract services from it. Some of these will be more independent than others.
In this post, Toptal Full-stack Developer Viktar Basharymau explains how his team extracted an app from the monolithic Rails application that powers Toptal, and how the new service’s technical stack was selected.

If a web application is big and old enough, there may come a time when you need to break it down into smaller, isolated parts and extract services from it. Some of these will be more independent than others.
In this post, Toptal Full-stack Developer Viktar Basharymau explains how his team extracted an app from the monolithic Rails application that powers Toptal, and how the new service’s technical stack was selected.

Viktar is a seasoned developer with strong analytical skills. He has production experience in Ruby, JS, C#, and Java, and is adept at FP.
Expertise
PREVIOUSLY AT

If a web application is big and old enough, there may come a time when you need to break it down into smaller, isolated parts and extract services from it, some of which will be more independent than others. Some of the reasons that could prompt such a decision include: reducing the time to run tests, being able to deploy different parts of the app independently, or enforcing boundaries between subsystems. Service extraction requires software engineers to make many vital decisions, and one of them is what tech stack to use for the new service.
In this post, we share a story about extracting a new service from a monolithic application – the Toptal Platform. We explain which technical stack we chose and why, and outline a few problems we encountered during the service implementation.
Toptal’s Chronicles service is an app that handles all user actions performed on the Toptal Platform. Actions are essentially log entries. When a user does something (e.g. publishes a blog post, approves a job, etc), a new log entry is created.
Although extracted from our Platform, it fundamentally doesn’t depend on it and can be used with any other app. This is why we are publishing a detailed account of the process and discussing a number of challenges our engineering team had to overcome while transitioning to the new stack.
There are a number of reasons behind our decision to extract the service and improve the stack:
- We wanted other services to be able to log events that could be displayed and used elsewhere.
- The size of the database tables storing history records grew quickly and non-linearly, incurring high operating costs.
- We deemed that the existing implementation was burdened by technical debt.
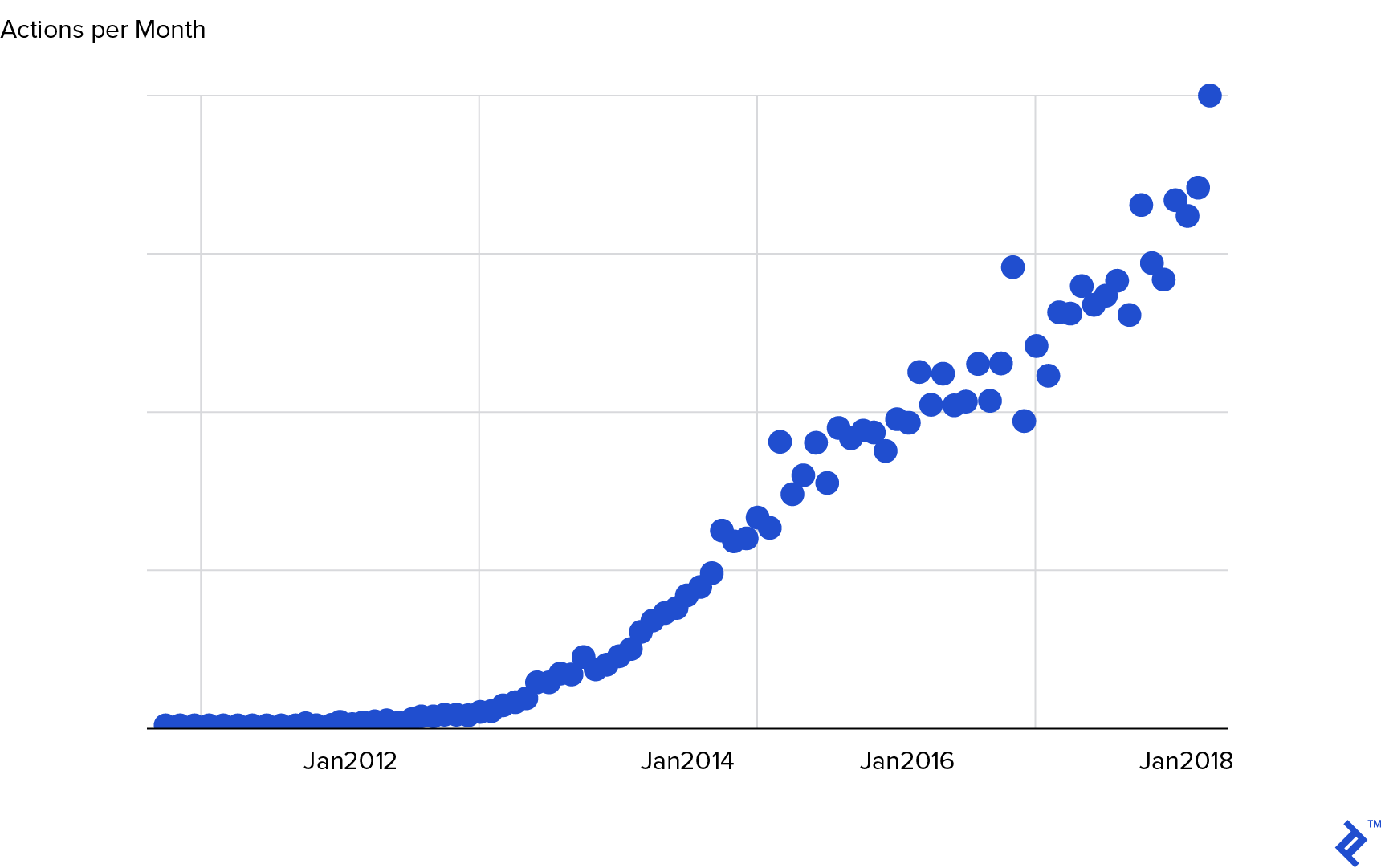
At first glance, it seemed like a straightforward initiative. However, dealing with alternative tech stacks tends to create unexpected drawbacks, and that’s what today’s article aims to address.
Architecture Overview
The Chronicles app consists of three parts that can be more or less independent and are run in separate Docker containers.
- Kafka consumer is a very thin Karafka-based Kafka consumer of entry creation messages. It enqueues all received messages to Sidekiq.
- Sidekiq worker is a worker that processes Kafka messages and creates entries in the database table.
-
GraphQL endpoints:
- Public endpoint exposes entry search API, which is used for various Platform functions (e.g., to render comment tooltips on screening buttons, or display the history of job changes).
- Internal endpoint provides the ability to create tag rules and templates from data migrations.
Chronicles used to connect to two different databases:
- Its own database (where we store tag rules and templates)
- The Platform database (where we store user-performed actions and their tags and taggings)
In the process of extracting the app, we migrated data from the Platform database and shut down the Platform connection.
Initial Plan
Initially, we decided to go with Hanami and all the ecosystem that it provides by default (a hanami-model backed by ROM.rb, dry-rb, hanami-newrelic, etc). Following a “standard” way of doing things promised us low friction, great implementation speed, and very good “googleability” of any problems that we may face. In addition, the hanami ecosystem is mature and popular, and the library is carefully maintained by respected members of the Ruby community.
Moreover, a large part of the system had already been implemented on the Platform side (e.g., GraphQL Entry Search endpoint and CreateEntry operation), so we planned to copy a lot of the code from Platform to Chronicles as is, without making any changes. This was also one of the key reasons we didn’t go with Elixir, as Elixir would not allow that.
We decided not to do Rails because it felt like overkill for such a small project, especially things like ActiveSupport, which wouldn’t provide many tangible benefits for our needs.
When the Plan Goes South
Although we did our best to stick to the plan, it soon got derailed for a number of reasons. One was our lack of experience with the chosen stack, followed by genuine issues with the stack itself, and then there was our non-standard setup (two databases). In the end, we decided to get rid of the hanami-model, and then of Hanami itself, replacing it with Sinatra.
We chose Sinatra because it’s an actively maintained library created 12 years ago, and since it’s one of the most popular libraries, everyone on the team had ample hands-on experience with it.
Incompatible Dependencies
The Chronicles extraction started in June 2019, and back then, Hanami was not compatible with the latest versions of dry-rb gems. Namely, the latest version of Hanami at the time (1.3.1) only supported dry-validation 0.12, and we wanted dry-validation 1.0.0. We planned to use contracts from dry-validation that were only introduced in 1.0.0.
Also, Kafka 1.2 is incompatible with dry gems, so we were using the repository version of it. At present, we are using 1.3.0.rc1, which depends on the newest dry gems.
Unnecessary Dependencies
Additionally, the Hanami gem included too many dependencies that we were not planning to use, such as hanami-cli, hanami-assets, hanami-mailer, hanami-view, and even hanami-controller. Also, looking at the hanami-model readme, it became clear that it supports only one database by default. On the other hand, ROM.rb, which the hanami-model is based on, supports multi-database configurations out of the box.
All in all, Hanami in general and the hanami-model in particular looked like an unnecessary level of abstraction.
So, 10 days after we made the first meaningful PR to Chronicles, we completely replaced hanami with Sinatra. We could have used pure Rack as well because we don’t need complex routing (we have four “static” endpoints - two GraphQL endpoints, the /ping endpoint, and sidekiq web interface), but we decided not to go too hardcore. Sinatra suited us just fine. If you’d like to learn more, check out our Sinatra and Sequel tutorial.
Dry-schema and Dry-validation Misunderstandings
It took us some time and a lot of trial-and-error to figure out how to “cook” dry-validation correctly.
params do
required(:url).filled(:string)
end
params do
required(:url).value(:string)
end
params do
optional(:url).value(:string?)
end
params do
optional(:url).filled(Types::String)
end
params do
optional(:url).filled(Types::Coercible::String)
end
In the snippet above, the url parameter is defined in several slightly different ways. Some definitions are equivalent, and others don’t make any sense. In the beginning, we couldn’t really tell the difference between all those definitions as we didn’t fully understand them. As a result, the first version of our contracts was quite messy. With time, we learned how to properly read and write DRY contracts, and now they look consistent and elegant–in fact, not only elegant, they are nothing short of beautiful. We even validate application configuration with the contracts.
Problems with ROM.rb and Sequel
ROM.rb and Sequel differ from ActiveRecord, no surprise. Our initial idea that we will be able to copy and paste most of the code from Platform failed. The problem is that the Platform part was very AR-heavy, so almost everything had to be rewritten in ROM/Sequel. We managed to copy only small portions of code which were framework-independent. Along the way, we faced a few frustrating issues and some bugs.
Filtering by Subquery
For example, it took me several hours to figure out how to make a subquery in ROM.rb/Sequel. This is something that I would write without even waking up in Rails: scope.where(sequence_code: subquery). In Sequel, though, it turned out to be not that easy.
def apply_subquery_filter(base_query, params)
subquery = as_subquery(build_subquery(params))
base_query.where { Sequel.lit('sequence_code IN ?', subquery) }
end
# This is a fixed version of https://github.com/rom-rb/rom-sql/blob/6fa344d7022b5cc9ad8e0d026448a32ca5b37f12/lib/rom/sql/relation/reading.rb#L998
# The original version has `unorder` on the subquery.
# The fix was merged: https://github.com/rom-rb/rom-sql/pull/342.
def as_subquery(relation)
attr = relation.schema.to_a[0]
subquery = relation.schema.project(attr).call(relation).dataset
ROM::SQL::Attribute[attr.type].meta(sql_expr: subquery)
end
So instead of a simple one-liner like base_query.where(sequence_code: bild_subquery(params)), we have to have a dozen of lines with non-trivial code, raw SQL fragments, and a multiline comment explaining what caused this unfortunate case of bloat.
Associations with Non-trivial Join Fields
The entry relation (performed_actions table) has a primary id field. However, to join with *taggings tables, it uses the sequence_code column. In ActiveRecord, it is expressed rather simply:
class PerformedAction < ApplicationRecord
has_many :feed_taggings,
class_name: 'PerformedActionFeedTagging',
foreign_key: 'performed_action_sequence_code',
primary_key: 'sequence_code',
end
class PerformedActionFeedTagging < ApplicationRecord
db_belongs_to :performed_action,
foreign_key: 'performed_action_sequence_code',
primary_key: 'sequence_code'
end
It is possible to write the same in ROM, too.
module Chronicles::Persistence::Relations::Entries < ROM::Relation[:sql]
struct_namespace Chronicles::Entities
auto_struct true
schema(:performed_actions, as: :entries) do
attribute :id, ROM::Types::Integer
attribute :sequence_code, ::Types::UUID
primary_key :id
associations do
has_many :access_taggings,
foreign_key: :performed_action_sequence_code,
primary_key: :sequence_code
end
end
end
module Chronicles::Persistence::Relations::AccessTaggings < ROM::Relation[:sql]
struct_namespace Chronicles::Entities
auto_struct true
schema(:performed_action_access_taggings, as: :access_taggings, infer: false) do
attribute :performed_action_sequence_code, ::Types::UUID
associations do
belongs_to :entry, foreign_key: :performed_action_sequence_code,
primary_key: :sequence_code,
null: false
end
end
end
There was a tiny problem with it, though. It would compile just fine but fail in runtime when you actually tried to use it.
[4] pry(main)> Chronicles::Persistence.relations[:platform][:entries].join(:access_taggings).limit(1).to_a
E, [2019-09-05T15:54:16.706292 #20153] ERROR -- : PG::UndefinedFunction: ERROR: operator does not exist: integer = uuid
LINE 1: ...ion_access_taggings" ON ("performed_actions"."id" = "perform...
^
HINT: No operator matches the given name and argument types. You might need to add explicit type casts.: SELECT <..snip..> FROM "performed_actions" INNER JOIN "performed_action_access_taggings" ON ("performed_actions"."id" = "performed_action_access_taggings"."performed_action_sequence_code") ORDER BY "performed_actions"."id" LIMIT 1
Sequel::DatabaseError: PG::UndefinedFunction: ERROR: operator does not exist: integer = uuid
LINE 1: ...ion_access_taggings" ON ("performed_actions"."id" = "perform...
We’re lucky that the types of id and sequence_code are different, so PG throws a type error. If the types were the same, who knows how many hours I would spend debugging this.
So, entries.join(:access_taggings) doesn’t work. What if we specify join condition explicitly? As in entries.join(:access_taggings, performed_action_sequence_code: :sequence_code), as the official documentation suggests.
[8] pry(main)> Chronicles::Persistence.relations[:platform][:entries].join(:access_taggings, performed_action_sequence_code: :sequence_code).limit(1).to_a
E, [2019-09-05T16:02:16.952972 #20153] ERROR -- : PG::UndefinedTable: ERROR: relation "access_taggings" does not exist
LINE 1: ...."updated_at" FROM "performed_actions" INNER JOIN "access_ta...
^: SELECT <snip> FROM "performed_actions" INNER JOIN "access_taggings" ON ("access_taggings"."performed_action_sequence_code" = "performed_actions"."sequence_code") ORDER BY "performed_actions"."id" LIMIT 1
Sequel::DatabaseError: PG::UndefinedTable: ERROR: relation "access_taggings" does not exist
Now it thinks that :access_taggings is a table name for some reason. Fine, let’s swap it with the actual table name.
[10] pry(main)> data = Chronicles::Persistence.relations[:platform][:entries].join(:performed_action_access_taggings, performed_action_sequence_code: :sequence_code).limit(1).to_a
=> [#<Chronicles::Entities::Entry id=22 subject_gid="gid://platform/Talent/124383" ... updated_at=2012-05-10 08:46:43 UTC>]
Finally, it returned something and didn’t fail, although it ended up with a leaky abstraction. The table name should not leak to the application code.
SQL Parameter Interpolation
There is a feature in Chronicles search which allows users to search by payload. The query looks like this: {operation: :EQ, path: ["flag", "gid"], value: "gid://plat/Flag/1"}, where path is always an array of strings, and value is any valid JSON value.
In ActiveRecord, it looks like this:
@scope.where('payload -> :path #> :value::jsonb', path: path, value: value.to_json)
In Sequel, I didn’t manage to properly interpolate :path, so I had to resort to that:
base_query.where(Sequel.lit("payload #> '{#{path.join(',')}}' = ?::jsonb", value.to_json))
Luckily, path here is properly validated so that it only contains alphanumeric characters, but this code still looks funny.
Silent Magic of ROM-factory
We used the rom-factory gem to simplify the creation of our models in tests. Several times, however, the code didn’t work as expected. Can you guess what is wrong with this test?
action1 = RomFactory[:action, app: 'plat', subject_type: 'Job', action: 'deleted']
action2 = RomFactory[:action, app: 'plat', subject_type: 'Job', action: 'updated']
expect(action1.id).not_to eq(action2.id)
No, the expectation is not failing, the expectation is fine.
The problem is that the second line fails with a unique constraint validation error. The reason is that action is not the attribute that the Action model has. The real name is action_name, so the right way to create actions should look like this:
RomFactory[:action, app: 'plat', subject_type: 'Job', action_name: 'deleted']
As the mistyped attribute was ignored, it falls back to the default one specified in the factory (action_name { 'created' }), and we have a unique constraint violation because we are trying to create two identical actions. We had to deal with this issue several times, which proved taxing.
Luckily, it was fixed in 0.9.0. Dependabot automatically sent us a pull request with the library update, which we merged after fixing a few mistyped attributes that we had in our tests.
General Ergonomics
This says it all:
# ActiveRecord
PerformedAction.count _# => 30232445_
# ROM
EntryRepository.new.root.count _# => 30232445_
And the difference is even greater in more complicated examples.
The Good Parts
It wasn’t all pain, sweat, and tears. There were many, many good things on our journey, and they far outweigh the negative aspects of the new stack. If that hadn’t been the case, we would not have done it in the first place.
Test Speed
It takes 5-10 seconds to run the whole test suite locally, and as long for RuboCop. CI time is much longer (3-4 minutes), but this is less of a problem because we can run everything locally anyway, thanks to which, anything failing on CI is much less likely.
The guard gem has become usable again. Imagine that you can write code and run tests on each save, giving you very fast feedback. This is very hard to imagine when working with the Platform.
Deploy Times
The time to deploy the extracted Chronicles app is just two minutes. Not lightning-fast, but still not bad. We deploy very often, so even minor improvements can generate substantial savings.
Application Performance
The most performance-intensive part of Chronicles is Entry search. For now, there are about 20 places in the Platform back end that fetch history entries from Chronicles. This means that the Chronicles’ response time contributes to the Platform’s 60-second budget for response time, so Chronicles has to be fast, which it is.
Despite the huge size of the actions log (30 million rows, and growing), the average response time is less than 100ms. Have a look at this beautiful chart:
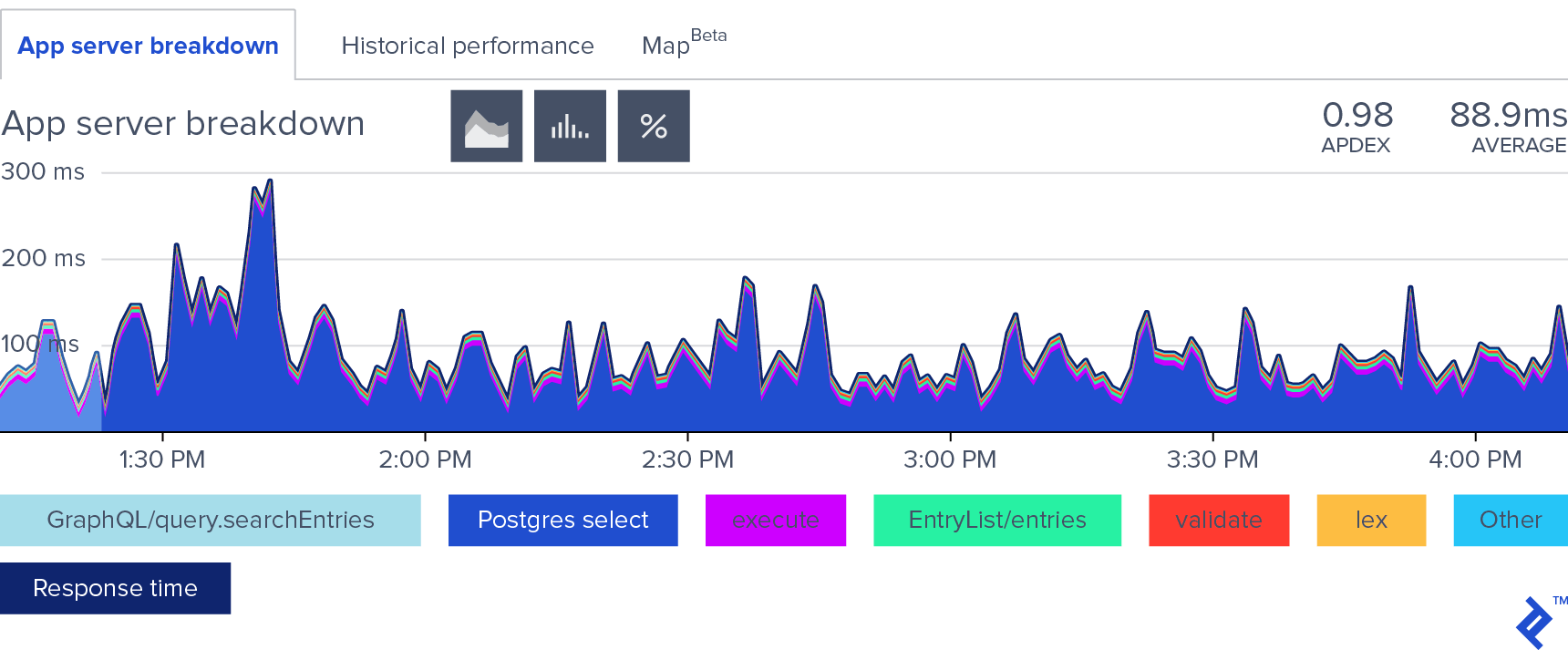
On average, 80-90% of the app time is spent in the database. That is what a proper performance chart should look like.
We still have some slow queries that may take tens of seconds, but we already have a plan how to eliminate them, allowing the extracted app to become even faster.
Structure
For our purposes, dry-validation is a very powerful and flexible tool. We pass all the input from the outside world through contracts, and it makes us confident that the input parameters are always well formed and of well-defined types.
There is no longer the need to call .to_s.to_sym.to_i in the application code, as all the data is cleaned up and typecasted at the borders of the app. In a sense, it brings strong types of sanity to the dynamic Ruby world. I can’t recommend it enough.
Final Words
Choosing a non-standard stack was not as straightforward as it initially seemed. We considered many aspects when selecting the framework and libraries to use for the new service: the current tech stack of the monolith application, the team’s familiarity with the new stack, how maintained the chosen stack is, and so on.
Even though we tried to make very careful and calculated decisions from the very beginning - we chose to use standard Hanami stack - we had to reconsider our stack along the way due to non-standard technical requirements of the project. We ended up with Sinatra and a DRY-based stack.
Would we choose Hanami again if we were to extract a new app? Probably yes. We now know more about the library and its pros and cons, so we could make more informed decisions right from the outset of any new project. However, we’d also seriously consider using a plain Sinatra/DRY.rb app.
All in all, the time invested in learning new frameworks, paradigms, or programming languages gives us a fresh perspective on our current tech stack. It’s always good to know what is available out there in order to enrich your toolbox. Each tool has its own unique use case—therefore, getting to know them better means having more of them at your disposal and turning them into a better fit for your application.
Understanding the basics
What is a tech stack?
A tech stack is a set of tools, programming languages, architecture patterns, and communication protocols that a team adheres to when developing an application.
How do you choose a technology stack for web application development?
In order to choose a tech stack for web application development, many factors need to be accounted for, including the development team’s familiarity with the tech stack, the stack’s suitability to the functional requirements of the application, and the long-term maintainability of solutions built with the chosen stack.
What is the tech stack of your current organization?
Our tech stack relies on Ruby on the back end, while on the front end, we use React and Typescript. The front end communicates with the back end via GraphQL and sometimes REST protocol. The back-end services’ asynchronous communication happens via Kafka, or synchronously using GraphQL/REST. We use PostgreSQL and Redis as our databases.
Viktar Basharymau
Warsaw, Poland
November 26, 2015
About the author
Viktar is a seasoned developer with strong analytical skills. He has production experience in Ruby, JS, C#, and Java, and is adept at FP.
Expertise
PREVIOUSLY AT